Robots.txt Nedir?
Robots.txt, bot tarayıcıların belirli sayfaları indeksleyip indekslememesi gerektiği talimatlarını içeren metin formatında bir dosyadır. Aynı zamanda tüm sitenizin kapıcısı olarak da bilinir. Bot tarayıcıların ilk hedefi, sitemap'ınıza veya herhangi bir sayfa veya klasöre erişmeden önce robots.txt dosyasını bulup okumaktır.
robots.txt ile daha spesifik olarak şunları yapabilirsiniz:
- Arama motoru botlarının sitenizi nasıl taraması gerektiğini düzenleyin
- Belli erişimler sağlayın
- Arama motoru örümceklerinin sayfa içeriğini nasıl indeksleyeceğine yardımcı olun
- Kullanıcılara içeriğin nasıl sunulacağını gösterin
Robots.txt, site/sayfa/URL düzeyinde yönergeleri içeren Robots Exclusion Protocol (R.E.P)'nin bir parçasıdır. Arama motoru botları tüm sitenizi taramaya devam edebilir, ancak belirli sayfaların zaman ve çaba harcamaya değer olup olmadığına onlara yardımcı olmak size bağlıdır.
Robots.txt Neden Gereklidir
Sitenizin düzgün çalışması için robots.txt dosyasına ihtiyacı yoktur. Bir robots.txt dosyasına ihtiyaç duymanızın temel nedenleri, botlar sayfanızı taramak için izin istediğinde, sayfa hakkında bilgi almaya çalışarak indekslemek için çaba göstermeleridir. Ayrıca, robots.txt dosyası olmayan bir web sitesi, temelde bot tarayıcıların sitenin uygun gördüğü şekilde indekslemesini istemektedir. Botların, robots.txt dosyası olmadan da sitenizi tarayacaklarını anlamak önemlidir.
robots.txt dosyanızın konumu da önemlidir çünkü tüm botlar www.123.com/robots.txt adresinde arayacaklardır. Eğer orada bir şey bulamazlarsa, sitenin robots.txt dosyası olmadığını varsayacak ve her şeyi indeksleyeceklerdir. Dosya bir ASCII veya UTF-8 metin dosyası olmalıdır. Kuralların büyük/küçük harfe duyarlı olduğunu belirtmek de önemlidir.
robots.txt'nin yapabilecekleri ve yapamayacakları bazı şeyler:
- Dosya, tarayıcıların web sitenizin belirli alanlarına erişimini kontrol etme yeteneğine sahiptir. Tüm web sitenin indekslenmesini engellemek mümkün olduğundan robots.txt'yi ayarlarken çok dikkatli olmanız gerekmektedir.
- Yinelenen içeriğin indekslenmesini ve arama motoru sonuçlarında görünmesini engeller.
- Dosya, tarayıcılar aynı anda birden fazla içerik yüklerken sunucuların aşırı yüklenmesini önlemek için tarama gecikmesini belirtir.
İşte zaman zaman sitenizde tarama yapabilecek bazı Googlebotlar:
| Web Tarayıcı | "User-Agent String" |
| Googlebot Haberleri | Googlebot-Haberler |
| Googlebot Görüntüler | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (özellikli telefon) | SAMSUNG-SGH-E250/1.0 Profil/MIDP-2.0 Konfigürasyon/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (uyumlu; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Google Akıllı Telefon | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (uyumlu; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (uyumlu; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (PPC açılış sayfası kalitesi) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google uygulama tarayıcısı (mobil için kaynakları getir) | AdsBot-Google-Mobile-Apps |
Burada ek botların bir listesini bulabilirsiniz.
- Dosyalar, site haritalarının yerinin belirlenmesine yardımcı olur.
- Ayrıca, arama motoru botlarının web sitesindeki çeşitli dosyaları, örneğin resimleri ve PDF'leri indekslemesini de engeller.
Bir bot web sitenizi ziyaret etmek istediğinde (örneğin, www.123.com), ilk olarak www.123.com/robots.txt adresini kontrol eder ve bulur:
User-agent: *
Disallow: /
Bu örnek, tüm (User-agents*) arama motoru botlarının web sitesini indekslememesi için talimat verir (Disallow: /).
Eğer Disallow'dan ileri eğik çizgiyi kaldırırsanız, aşağıdaki örnekte olduğu gibi,
User-agent: *
Yasakla:
botlar, web sitesindeki her şeyi tarama ve indeksleme yeteneğine sahip olacaklar. İşte bu yüzden robots.txt sözdizimini anlamanın önemi büyüktür.
robots.txt sözdizimini anlama
Robots.txt sözdizimi, robots.txt dosyalarının "dili" olarak düşünülebilir. Bir robots.txt dosyasında karşılaşabileceğiniz 5 yaygın terim vardır. Bunlar:
- Kullanıcı aracısı: Tarama talimatları verdiğiniz belirli web tarayıcısı (genellikle bir arama motoru). Çoğu kullanıcı aracısının listesi burada bulunabilir.
- Disallow: Bir kullanıcı aracısına belirli bir URL'yi taramamasını söylemek için kullanılan komut. Her URL için yalnızca bir "Disallow:" satırına izin verilir.
- Allow (Yalnızca Googlebot için geçerlidir): Bu komut, Googlebot'un ana sayfası veya üst klasörü engellenmiş olsa bile bir sayfaya veya alt klasöre erişebileceğini belirtir.
- Crawl-delay: Bir tarayıcının sayfa içeriğini yükleyip taramadan önce beklemesi gereken milisaniye sayısı. Googlebot'un bu komutu tanımadığını ancak tarama hızının Google Arama Konsolu'nda ayarlanabileceğini unutmayın.
- Site haritası: Bir URL ile ilişkilendirilmiş herhangi bir XML site haritasının yerini belirtmek için kullanılır. Bu komutun sadece Google, Ask, Bing ve Yahoo tarafından desteklendiğini unutmayın.
Robots.txt talimat sonuçları
robots.txt talimatları verdiğinizde üç sonuç beklersiniz:
- Tam izin
- Tam yasak
- Koşullu izin
Hadi her birini aşağıda inceleyelim.
Tam İzin
Bu sonuç, web sitenizdeki tüm içeriğin taranabileceği anlamına gelir. Robots.txt dosyaları, arama motoru botlarının taramasını engellemek için tasarlanmıştır, bu yüzden bu komut çok önemli olabilir.
Bu sonuç, web sitenizde hiç robots.txt dosyanızın olmadığı anlamına gelebilir. Ona sahip olmasanız bile, arama motoru botları yine de sitenizde onu arayacaklar. Eğer onu bulamazlarsa, web sitenizin tüm bölümlerini taramaya devam edeceklerdir.
Bu sonucun altındaki diğer seçenek, bir robots.txt dosyası oluşturmak fakat onu boş bırakmaktır. Örümcek tarama yapmak için geldiğinde, robots.txt dosyasını tanıyacak ve hatta okuyacaktır. Orada hiçbir şey bulamadığı için, siteyi taramaya devam edecektir.
Eğer bir robots.txt dosyanız varsa ve içinde aşağıdaki iki satır bulunuyorsa,
User-agent:*
Yasakla:
arama motoru örümceği web sitenizi taramaya başlayacak, robots.txt dosyasını tanıyacak ve onu okuyacak. İkinci satıra gelecek ve ardından sitenin geri kalanını taramaya devam edecek.
Tamamen Yasaklama
Burada, hiçbir içerik tarama ve indeksleme işlemine tabi tutulmayacak. Bu komut şu satır tarafından verilir:
User-agent:*
Disallow:/
Bir içerikten bahsetmediğimiz zaman, web sitesinden (içerik, sayfalar vb.) hiçbir şeyin taranamayacağı anlamına gelir. Bu hiçbir zaman iyi bir fikir değildir.
Koşullu İzin
Bu, yalnızca web sitesindeki belirli içeriklerin taranabileceği anlamına gelir.
Bir koşullu izin şu formatta olur:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
robots.txt sözdiziminin tamamını burada bulabilirsiniz.
Engellenmiş sayfaların, aşağıdaki resimde gösterildiği gibi URL'yi engelleme işlemi yapsanız bile hala indekslenebileceğini unutmayın:
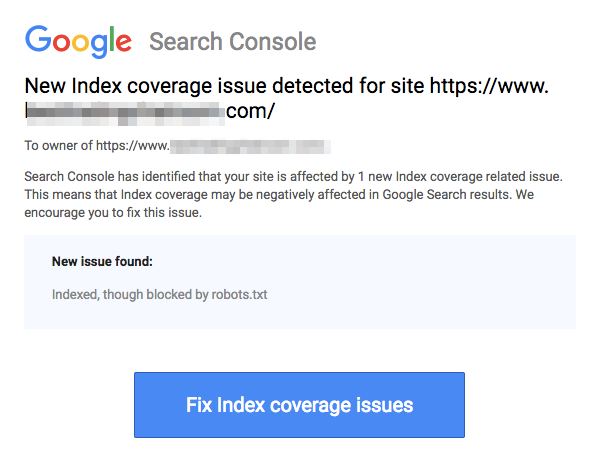
Arama motorlarından yukarıdaki ekran görüntüsünde olduğu gibi URL'nizin indekslendiğine dair bir e-posta alabilirsiniz. Eğer yasaklanmış URL'niz diğer siteler tarafından, örneğin linklerdeki çapa metinlerinde bağlantı verilmişse, indekslenecektir. Buna çözüm olarak 1) dosyalarınızı sunucunuzda şifre ile koruma altına alabilir, 2) noindex meta etiketini kullanabilir veya 3) sayfayı tamamen kaldırabilirsiniz.
Bir robot hala robots.txt dosyamı tarayıp yok sayabilir mi?
Evet. bir robotun robots.txt'yi atlayabilmesi mümkündür. Bunun nedeni, Google'ın bir sayfanın indekslenip indekslenmeyeceğine karar vermek için dış bilgiler ve gelen bağlantılar gibi diğer faktörleri kullanmasıdır. Eğer bir sayfanın hiç indekslenmesini istemiyorsanız, noindex robots meta etiketini kullanmalısınız. Başka bir seçenek de X-Robots-Tag HTTP başlığını kullanmaktır.
Sadece kötü robotları engelleyebilir miyim?
Teoride kötü robotları engellemek mümkündür, ancak pratikte bunu yapmak zor olabilir. Gelin, bunu yapmanın bazı yollarına bakalım:
- Kötü bir robotu hariç tutarak engelleyebilirsiniz. Ancak, belirli robotun User-Agent alanında taradığı ismi bilmek zorundasınız. Daha sonra robots.txt dosyanıza kötü robotu hariç tutan bir bölüm eklemeniz gerekmektedir.
- Sunucu yapılandırması. Bu, kötü robotun işleminin tek bir IP adresinden yapılması durumunda işe yarar. Sunucu yapılandırması veya bir ağ güvenlik duvarı, kötü robotun web sunucunuza erişimini engelleyecektir.
- Gelişmiş güvenlik duvarı kuralı yapılandırmalarını kullanma. Bunlar, kötü robotun kopyalarının bulunduğu çeşitli IP adreslerine erişimi otomatik olarak engelleyecektir. Çeşitli IP adreslerinde faaliyet gösteren botların iyi bir örneği, daha büyük bir Botnet'in parçası bile olabilecek ele geçirilmiş PC'lerdir (Botnet hakkında daha fazla bilgi edinin burada).
Eğer kötü robot tek bir IP adresinden çalışıyorsa, sunucu yapılandırması veya bir ağ güvenlik duvarı ile web sunucunuza erişimini engelleyebilirsiniz.
Eğer robotun kopyaları birçok farklı IP adresinde çalışıyorsa, onları engellemek daha zor hale gelir. Bu durumda en iyi seçenek, çok sayıda bağlantı kuran IP adreslerine otomatik olarak erişimi engelleyen gelişmiş güvenlik duvarı kural yapılandırmalarını kullanmaktır; ne yazık ki, bu iyi botların erişimini de etkileyebilir.
robots.txt kullanırken en iyi SEO uygulamaları nelerdir?
Bu noktada, bu oldukça zorlu robots.txt sularında nasıl yol alacağınızı merak ediyor olabilirsiniz. Bunu daha detaylı bir şekilde inceleyelim:
- Sitenizde taramasını istediğiniz herhangi bir içeriği veya bölümü engellemediğinizden emin olun.
- Link equity'nin robots.txt ile (ki bu pratikte engellenmiş demektir) engellenmiş bir sayfadan link hedefine aktarılmasını istiyorsanız, robots.txt'den farklı bir engelleme mekanizması kullanın.
- Arama motoru sonuçlarında özel kullanıcı bilgileri gibi hassas verilerin görünmesini önlemek için robots.txt kullanmayın. Bunu yapmak, özel kullanıcı bilgileri içeren sayfalara diğer sayfaların bağlantı vermesine ve bu sayede sayfanın indekslenmesine neden olabilir. Bu durumda, robots.txt atlatılmış olur. Burada araştırabileceğiniz diğer seçenekler arasında şifre koruması veya noindex meta yönergesi bulunmaktadır.
- Bir arama motorunun tarama robotları için her biri için yönergeler belirtmeye gerek yoktur, çünkü aynı arama motoruna ait olan çoğu kullanıcı aracı, aynı kuralları takip eder. Google, arama motorları için Googlebot ve resim aramaları için Googlebot Image kullanır. Her tarama robotunu nasıl belirleyeceğinizi bilmekten gelen tek avantaj, sitenizdeki içeriğin tam olarak nasıl taranacağını ince ayar yapabilmenizdir.
- robots.txt dosyasını değiştirdiyseniz ve Google'ın bunu daha hızlı güncellemesini istiyorsanız, doğrudan Google'a gönderin. Bunu nasıl yapacağınıza dair talimatlar için buraya tıklayın. Arama motorlarının robots.txt içeriğini önbelleğe aldığını ve önbelleğe alınan içeriği en az günde bir kez güncellediğini unutmamak önemlidir.
Temel robots.txt kuralları
Artık robots.txt ile ilgili temel bir SEO anlayışına sahip olduğunuza göre, robots.txt kullanırken aklınızda bulundurmanız gereken şeyler nelerdir? Bu bölümde, robots.txt kullanırken takip edilmesi gereken bazı yönergeleri inceliyoruz, ancak tüm sözdizimini gerçekten okumanın önemli olduğunu unutmayın.
Biçim ve konum
Robots.txt dosyası oluşturmak için kullanmayı tercih ettiğiniz metin editörü, standart ASCII veya UTF-8 metin dosyaları oluşturabilme özelliğine sahip olmalıdır. Bir kelime işlemci kullanmak iyi bir fikir değildir çünkü taramayı etkileyebilecek bazı karakterler eklenmiş olabilir.
Neredeyse herhangi bir metin düzenleyici robots.txt dosyanızı oluşturmak için kullanılabilirken, bu araç sitenizde test yapılabilmesi açısından şiddetle tavsiye edilir.
İşte biçim ve konum hakkında daha fazla yönerge:
- Oluşturduğunuz dosyaya “robots.txt” adını vermelisiniz çünkü dosya adı büyük/küçük harfe duyarlıdır. Büyük harf karakterleri kullanılmaz.
- Tüm sitede yalnızca bir robots.txt dosyasına sahip olabilirsiniz.
- robots.txt dosyası yalnızca bir yerde bulunur: Uygulandığı web sitesi ana dizini. Alt dizine yerleştirilemeyeceğini unutmayın. Eğer web siteniz http://www.123.com/, o zaman robots.txt dosyasının yeri http://www.123.com/robots.txt, değilhttp://www.123.com/pages/robots.txt. robots.txt dosyasının alt alan adlarına (subdomains) uygulanabileceğini unutmayın (http://website.123.com/robots.txt) ve hatta standart olmayan portlar, örneğinhttp://www.123.com: 8181/robots.txt.
Yukarıda bahsedildiği gibi, robots.txt, hassas kişisel bilgilerin dizine eklenmesini önlemek için en iyi yöntem değildir. Bu, özellikle yeni uygulamaya konan GDPR ile şimdi geçerli bir endişedir. Veri gizliliği tehlikeye atılmamalıdır. Nokta.
robots.txt'nin hassas verileri arama sonuçlarında göstermemesini nasıl sağlarsınız?
Web üzerinde "listelenemeyen" ayrı bir alt dizin kullanmak, hassas materyalin dağıtımını önleyecektir. Sunucu yapılandırmasını kullanarak bunun "listelenemeyeceğinden" emin olabilirsiniz. Robots.txt'nin ziyaret edip indekslemesini istemediğiniz tüm dosyaları bu alt dizinde saklayın.
robots.txt dosyasında sayfaların veya dizinlerin listelenmesi istenmeyen erişime neden olmaz mı?
Yukarıda bahsedildiği gibi, indekslenmesini istemediğiniz tüm dosyaları ayrı bir alt dizine koyup, ardından sunucu yapılandırmaları aracılığıyla listelenemez hale getirmek, bu dosyaların arama sonuçlarında görünmemesini sağlamalıdır. robots.txt dosyasında yapacağınız tek listeleme, dizin adı olacaktır. Bu dosyalara erişmenin tek yolu, dosyalardan birine doğrudan bir bağlantı üzerinden olacaktır.
İşte bir örnek:
Yerine
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Kullan
User-Agent:*
Disallow:/norobots/
Daha sonra "norobots" adında bir dizin oluşturmanız gerekiyor, bu dizin içinde foo.html ve bar.html dosyaları bulunacak. Sunucu yapılandırmalarınızın "norobots" dizini için bir dizin listesi oluşturmaması konusunda açık olması gerektiğini unutmayın.
Bu çok güvenli bir yaklaşım olmayabilir çünkü sitenize saldıran kişi veya bot, dizin içindeki dosyaları göremese bile "norobots" dizininin var olduğunu hala görebilir. Ancak, birisi bu dosyalara kendi web sitelerinde bir link yayınlayabilir veya daha da kötüsü, link, herkesin erişebileceği bir log dosyasında görünebilir (örneğin, bir web sunucusu logu referans olarak). Ayrıca bir sunucu yanlış yapılandırması da mümkündür, bu da bir dizin listelemesine yol açar.
Bu ne anlama geliyor? Robots.txt, basit bir nedenle erişimi kontrol etmede size yardımcı olamaz; çünkü bu amaç için tasarlanmamıştır. İyi bir örnek “Giriş yasaktır” işaretidir. Talimatı ihlal edecek insanlar hala olacaktır.
Eğer sadece yetkili kişiler tarafından erişilmesini istediğiniz dosyalar varsa, sunucu yapılandırmaları kimlik doğrulama konusunda yardımcı olacaktır. Eğer bir CMS (İçerik Yönetim Sistemi) kullanıyorsanız, bireysel sayfalar ve kaynak koleksiyonları üzerinde erişim kontrollerine sahipsiniz.
robots.txt dosyasını SEO için optimize edebilir misiniz?
Kesinlikle. Robots.txt'yi optimize etmek için en iyi rehber site içeriğidir. Hızlı bir hatırlatma: Robots.txt, sayfaların arama motoru botları tarafından taranmasını engellemek için asla kullanılmamalıdır. Yalnızca, örneğin wp-admin gibi, halka açık olmayan web sitenizin bölümlerini engellemek için kullanın.
Bu, Neil Patel’in web sitelerinden birindeki giriş sayfası için kullanılan engelleme satırıdır:
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
Bu disallow satırını, girişinizin indekslenmesini engellemek için kullanabilirsiniz.
Bazı belirli sayfaların indekslenmesini istemiyorsanız, yukarıdakiyle aynı komutu kullanın. Bir örnek:
User-agent:*
Disallow:/sayfa/
Kapatmadan önce dizine eklenmesini istemediğiniz sayfayı eğik çizgi sonrasında belirtin. Örneğin:
User-agent:*
Disallow:/page/thank-you/
İndekslenmesini istemediğiniz bazı sayfalar nelerdir?
- Kasten yapılan çift içerik. Bu ne anlama geliyor? Bazen belirli bir amaçla kasıtlı olarak çift içerik oluşturursunuz. İyi bir örnek, belirli bir web sayfasının yazıcı dostu versiyonudur. Aynı içeriğin yazıcı dostu versiyonunun indekslenmesini engellemek için robots.txt kullanabilirsiniz.
- Teşekkür sayfaları. Bu sayfanın indekslenmesini engellemek istemenizin nedeni basittir: Bu, satış hunisinin son adımı olması gereken bir sayfadır. Ziyaretçileriniz bu sayfaya geldiklerinde, tüm satış hunisinden geçmiş olmalıdırlar. Eğer bu sayfa indekslenirse, potansiyel müşterileri kaçırma ihtimaliniz olabilir veya yanlış müşteri adayları alabilirsiniz.
Böyle bir sayfayı engellemek için komut şudur:
Disallow:/thank-you/
Noindex ve NoFollow
Bu makale boyunca söylediğimiz gibi, robots.txt kullanmak sayfanızın indekslenmeyeceğinin %100 garantisi değildir. Engellenmiş sayfanızın gerçekten indekslenmediğinden emin olmanın iki yoluna bakalım.
noindex direktifi
Bu, disallow komutu ile birlikte çalışır. Her ikisini de yönergenizde şu şekilde kullanın:
Disallow:/thank-you/
nofollow yönergesi
Bu, Google botlarının bir sayfadaki bağlantıları taramaması için özellikle talimat vermek amacıyla kullanılır. Bu, robots.txt dosyasının bir parçası değildir. Sayfaların taranıp indekslenmesini engellemek için nofollow komutunu kullanmak istiyorsanız, indekslenmesini istemediğiniz belirli sayfanın kaynak kodunu bulmanız gerekmektedir.
Açılış ve kapanış head etiketleri arasına bunu yapıştırın:
<meta name = “robots” content=”takip etme”>
“nofollow” ve “noindex” etiketlerini aynı anda kullanabilirsiniz. Bu kod satırını kullanın:
<meta name = “robots” content=”noindex,nofollow”>
robots.txt Oluşturma
Eğer robots.txt dosyasını yazarken gerekli tüm formatları ve sözdizimini anlamak ve takip etmek zor buluyorsanız, süreci basitleştiren araçlar kullanabilirsiniz. İyi bir örnek, bizim ücretsiz robots.txt oluşturucumuz.
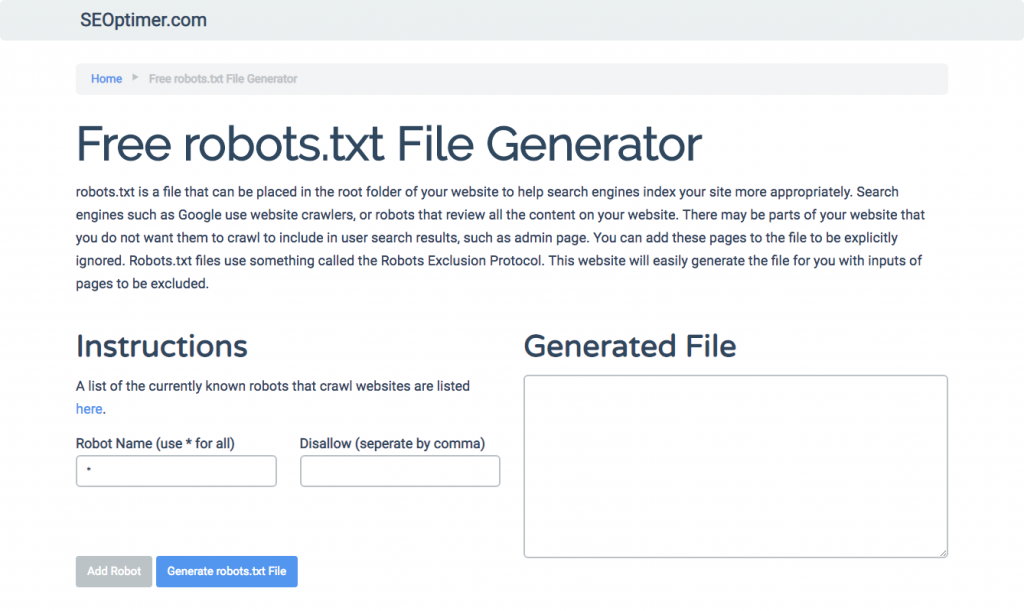
Bu araç, web sitenizde ihtiyaç duyduğunuz sonuç türünü seçmenize ve eklemek istediğiniz dosya veya dizinleri belirlemenize olanak tanır. Dosyanızı bile test edebilir ve rakiplerinizin nasıl performans gösterdiğini görebilirsiniz.
robots.txt dosyanızı Test Etme
Robots.txt dosyanızın beklenildiği gibi çalıştığını test etmeniz gerekiyor.
Google'ın robots.txt test aracını kullanın.
Bunu yapmak için Webmaster hesabınıza giriş yapın.
- Ardından, mülkünüzü seçin. Bu durumda, bu sizin web sitenizdir.
- Sol taraftaki kenar çubuğunda "tarama"ya tıklayın.
- "robots.txt test edici"ye tıklayın.
- Mevcut kodun herhangi birini yeni robots.txt dosyanızla değiştirin.
- "test et"e tıklayın.
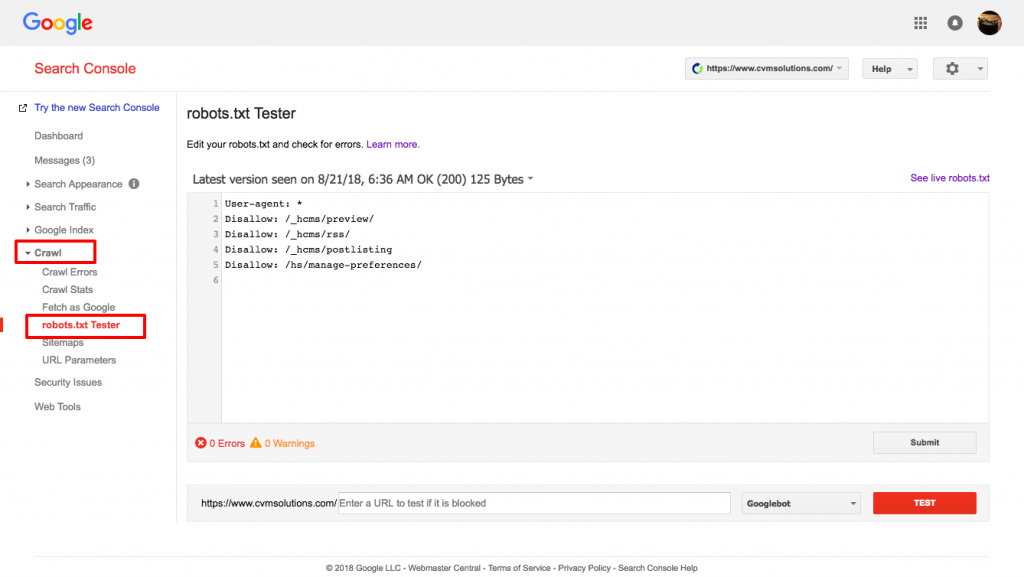
Dosya geçerliyse bir metin kutusu "izin verildi" görebilmelisiniz. Daha fazla bilgi için, Google robots.txt test cihazı hakkındaki bu ayrıntılı rehberi inceleyin.
Eğer dosyanız geçerliyse, şimdi onu kök dizininize yüklemenin veya orada başka bir robots.txt dosyası varsa kaydetmenin zamanı geldi.
WordPress sitenize robots.txt nasıl eklenir
WordPress dosyanıza bir robots.txt dosyası eklemek için, eklenti ve FTP seçeneklerini ele alacağız.
Eklenti seçeneği için, All in One SEO Pack gibi bir eklenti kullanabilirsiniz
Bunu yapmak için WordPress kontrol panelinize giriş yapın
Aşağıya doğru kaydırın ta ki "eklentiler"e gelene kadar
“yeni ekle”ye tıklayın
“arama eklentileri”ne gidin
“All in One SEO Pack” yazın
Kur ve etkinleştir
All in One SEO eklentisinin Genel Ayarlar bölümünde, robots.txt dosyanıza dahil edilecek noindex ve nofollow kurallarını yapılandırabilirsiniz.
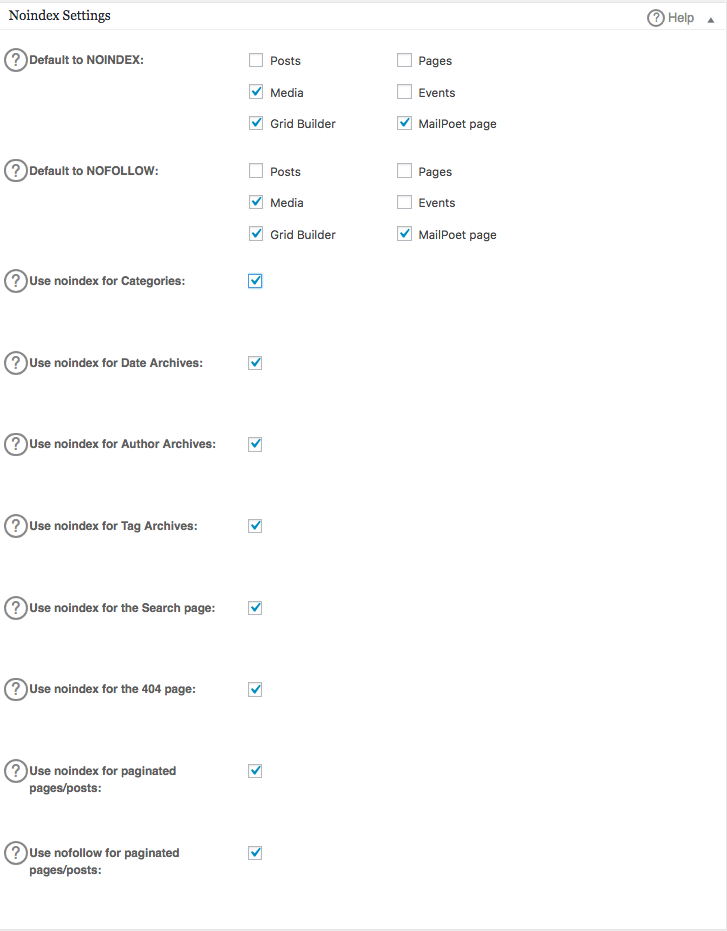
Hangi URL'lerin NOINDEX, NOFOLLOW olması gerektiğini belirleyebilirsiniz. Bunları işaretlemezseniz varsayılan olarak indekslenecektir:
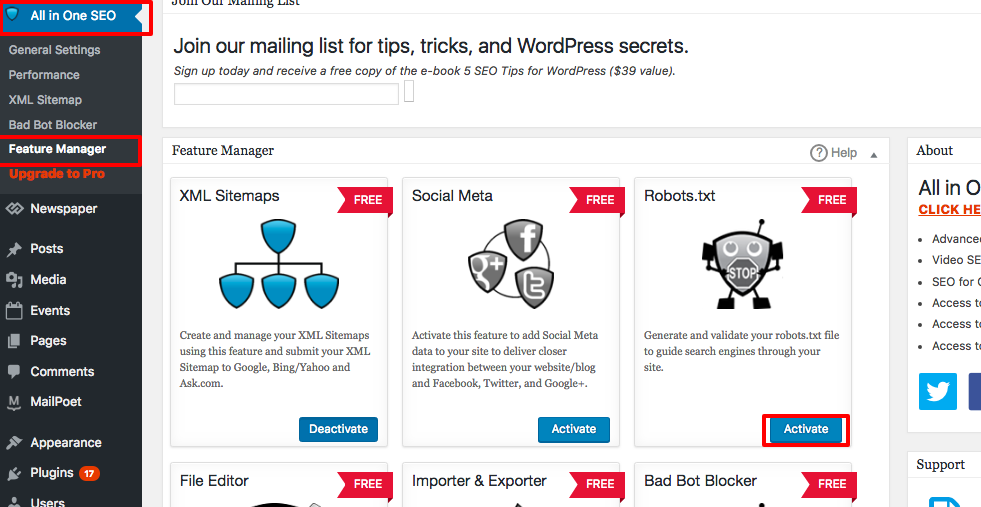
robots.txt dosyanızda ileri düzey kurallar oluşturmak için, özellik yöneticisine tıklayın, ardından robots.txt'nin hemen altındaki etkinleştir butonuna basın.
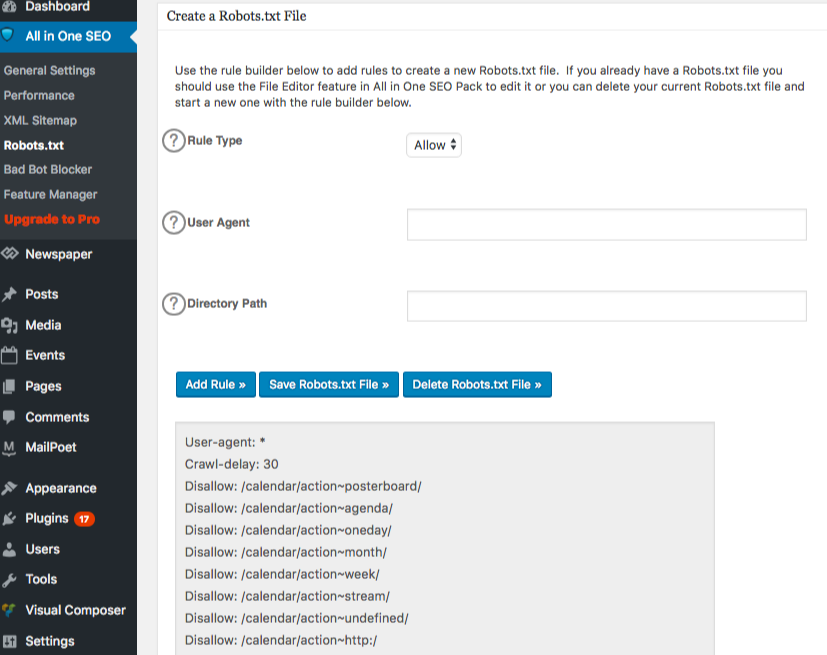
Robots.txt artık özellik yöneticisinin hemen altında görünüyor. Üzerine tıklayın. "robots.txt dosyası oluştur" adında bir bölüm göreceksiniz.
Site için istediğiniz kuralları seçmenize ve doldurmanıza izin veren bir kural oluşturucu bölüm bulunmaktadır, indekslenmesini istemediğiniz şeylere bağlı olarak.
Kuralı oluşturmayı bitirdiğinizde, “kural ekle” butonuna tıklayın.
Kural daha sonra oluşturulan robots.txt klasörü altında listelenecektir.
Bir mesaj göreceksiniz ki bu “All in One Options” güncellendiğini belirtir.
Bir başka yöntem olarak, robots.txt dosyanızı FileZilla gibi FTP (Dosya Aktarım Protokolü) istemcinize doğrudan yükleyebilirsiniz.
Robots.txt dosyanızı oluşturduktan sonra, bulabilir ve değiştirebilirsiniz. Robots.txt dosyanız şu konumda bulunacak: "/applications/[KLASÖR ADI]/public_html."
Wix'teki robots.txt dosyanızı nasıl düzenlersiniz
Wix, web sitesi oluşturma platformunu kullanan web siteleri için bir robots.txt dosyası oluşturur. Bunu görüntülemek için, alan adınıza “/robots.txt” ekleyin. Robots.txt'ye eklenen dosyalar, örneğin SEO değerine katkıda bulunmayan noflashhtml bağlantıları gibi, Wix sitelerinin yapısıyla ilgilidir.
Wix tarafından desteklenen bir siteye sahipseniz robots.txt dosyanızı düzenleyemezsiniz. İndekslenmesini istemediğiniz sayfalara “noindex etiketi” ekleyerek gibi diğer seçenekleri kullanabilirsiniz.
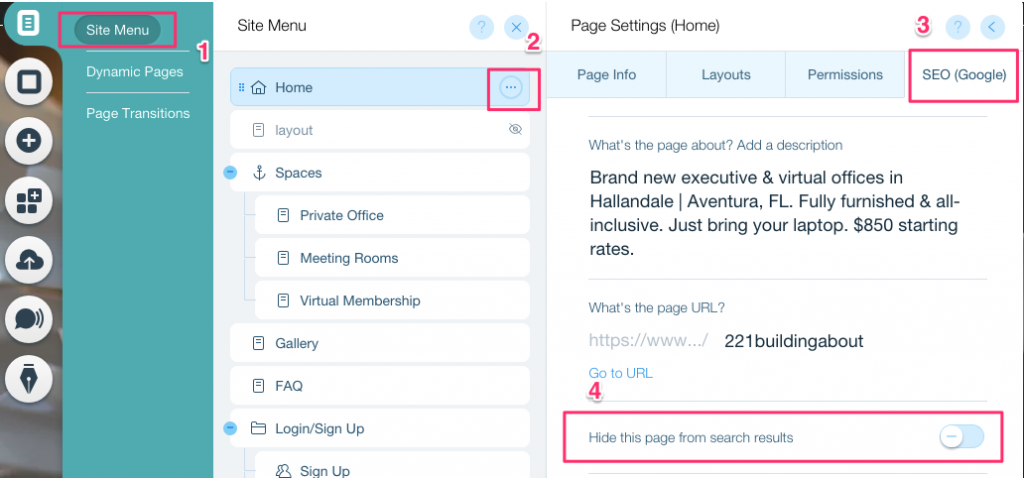
Belirli bir sayfa için noindex etiketi oluşturmak:
- Site Menüsü'ne tıklayın
- Belirli sayfa için Ayarlar seçeneğine tıklayın
- SEO (Google) etiketi'ni seçin
- Arama sonuçlarından bu sayfayı gizle'yi açın
Shopify'da robots.txt dosyanızı nasıl düzenlersiniz
Wix ile olduğu gibi, Shopify da sitenize düzenlenemez bir robots.txt dosyası otomatik olarak ekler. Bazı sayfaların indekslenmesini istemiyorsanız, "noindex etiketi" eklemeniz veya sayfayı yayından kaldırmanız gerekir. İndekslenmesini istemediğiniz sayfaların başlık bölümüne meta etiketleri de ekleyebilirsiniz. Başlığınıza eklemeniz gereken şey şudur:
<meta name= “robots” content = “noindex”>
Shopify, arama motorlarından sayfaları nasıl gizleyeceğiniz hakkında detaylı bir rehber hazırladı ki bunu takip edebilirsiniz.
Başka bir seçenek, Sitemap & NoIndex Manager adında bir uygulama indirmektir. Shopify sitenizdeki her sayfa için basitçe noindex veya nofollow seçeneklerini işaretleyebilirsiniz: