Jeśli otrzymałeś ostrzeżenie ‘Zaindeksowane, chociaż zablokowane przez robots.txt’ w Google Search Console, będziesz chciał to naprawić jak najszybciej, ponieważ może to wpływać na zdolność Twoich stron do rankingu w ogóle na stronach wyników wyszukiwania (SERPS).
Plik robots.txt to plik znajdujący się w katalogu Twojej strony internetowej, który zawiera instrukcje dla robotów wyszukiwarek, takich jak bot Google'a, które pliki powinny, a których nie powinny przeglądać.
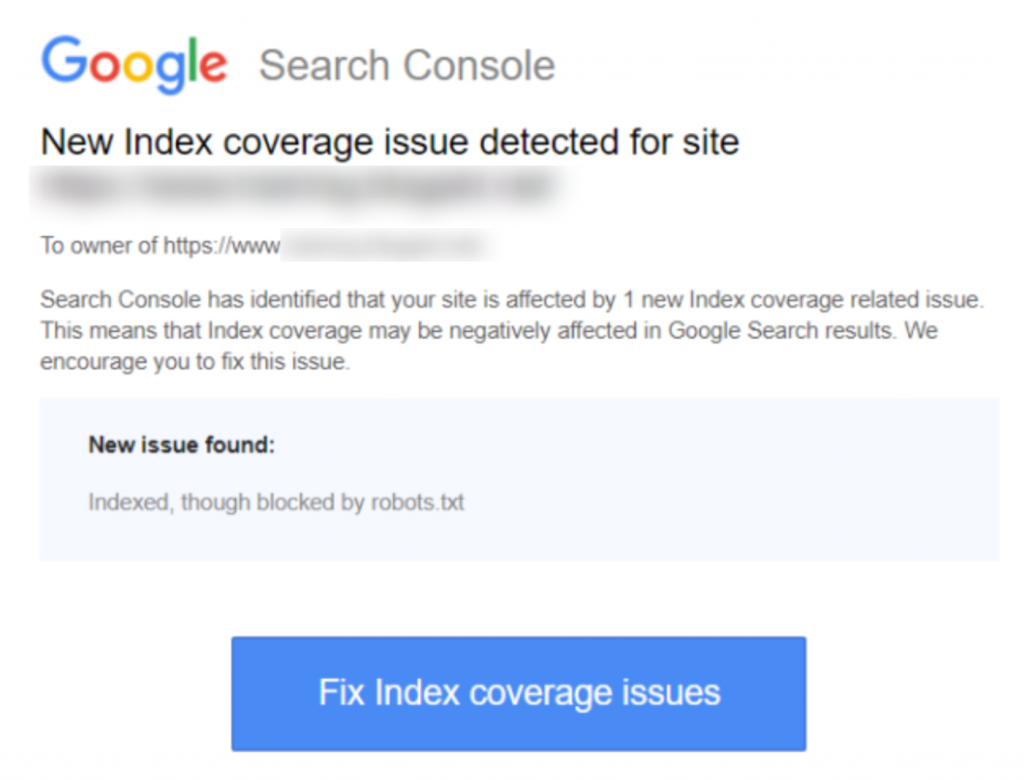
„Zaindeksowane, choć zablokowane przez robots.txt” oznacza, że Google znalazł twoją stronę, ale znalazł również instrukcję ignorowania jej w twoim pliku robots (co oznacza, że nie pojawi się w wynikach).
Czasami jest to celowe, a czasami przypadkowe, z wielu powodów opisanych poniżej, i może być naprawione.
Oto zrzut ekranu powiadomienia:
Zidentyfikuj dotkniętą(e) stronę(strony) lub adres(y) URL
Jeśli otrzymałeś powiadomienie z Google Search Console (GSC), musisz zidentyfikować konkretną(e) stronę(y) lub adres(y) URL, o które chodzi.
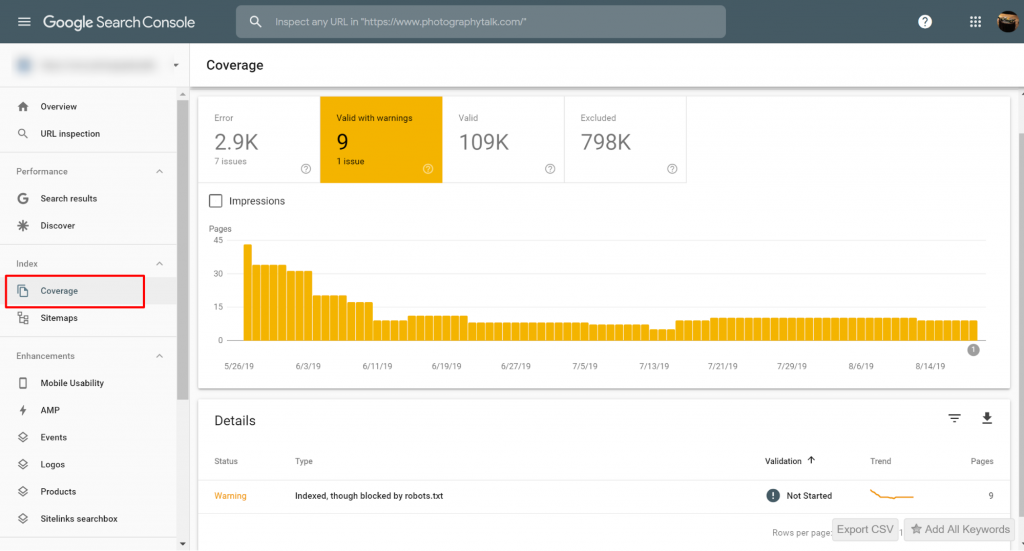
Możesz przeglądać strony z problemami Indexed, though blocked by robots.txt w Google Search Console>>Coverage. Jeśli nie widzisz etykiety ostrzegawczej, to jesteś wolny i bez przeszkód.
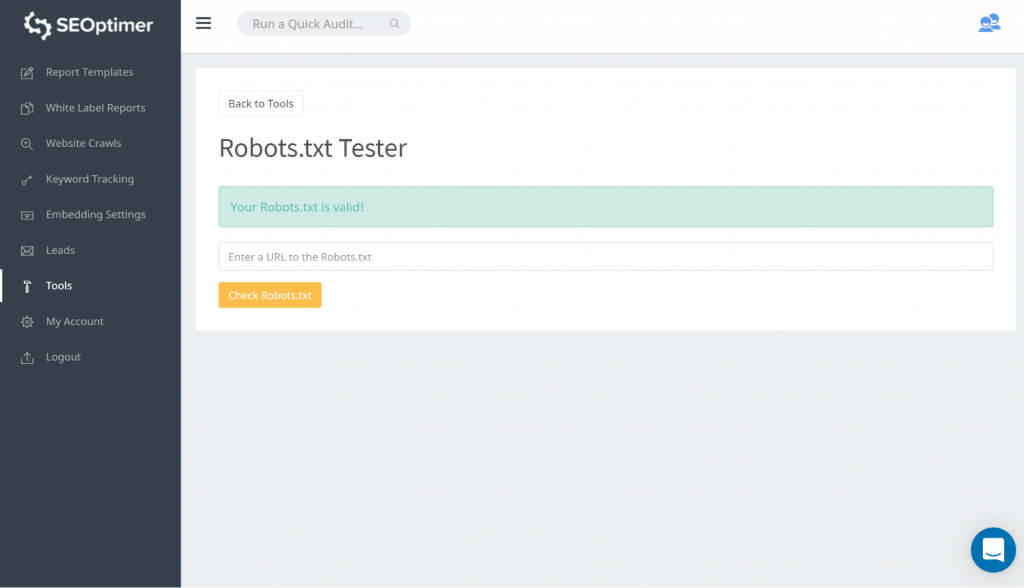
Sposób na przetestowanie twojego pliku robots.txt to użycie naszego testera robots.txt. Możesz odkryć, że nie masz nic przeciwko temu, aby to, co jest blokowane, pozostało „zablokowane”. W takim przypadku nie musisz podejmować żadnych działań.
Możesz również śledzić ten link GSC. Następnie musisz:
- Otwórz listę zablokowanych zasobów i wybierz domenę.
- Kliknij każdy zasób. Powinieneś zobaczyć to okienko:
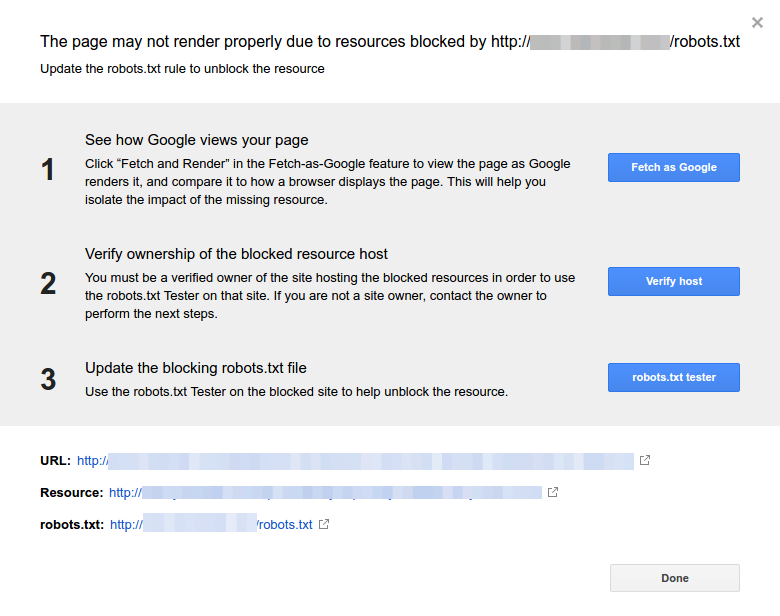
Zidentyfikuj powód powiadomienia
Powiadomienie może wynikać z kilku powodów. Oto najczęstsze z nich:
Ale przede wszystkim, to niekoniecznie problem, jeśli są strony zablokowane przez robots.txt., Mogło to być zaprojektowane z powodów takich jak, na przykład, deweloper chcący zablokować niepotrzebne / kategorie stron lub duplikaty. Więc, jakie są rozbieżności?
Błędny format adresu URL
Czasami problem może wynikać z URL, który tak naprawdę nie jest stroną. Na przykład, jeśli URL to https://www.seoptimer.com/?s=digital+marketing, musisz wiedzieć, do jakiej strony URL się rozwiązuje.
Jeśli jest to strona zawierająca istotne treści, które naprawdę chcesz, aby Twoi użytkownicy zobaczyli, wtedy musisz zmienić URL. Jest to możliwe w Systemach Zarządzania Treścią (CMS) takich jak Wordpress, gdzie możesz edytować slug strony.
Jeśli strona nie jest ważna, lub w naszym przykładzie /?s=digital+marketing, jest to zapytanie wyszukiwania z naszego bloga, to nie ma potrzeby naprawiać błędu GSC.
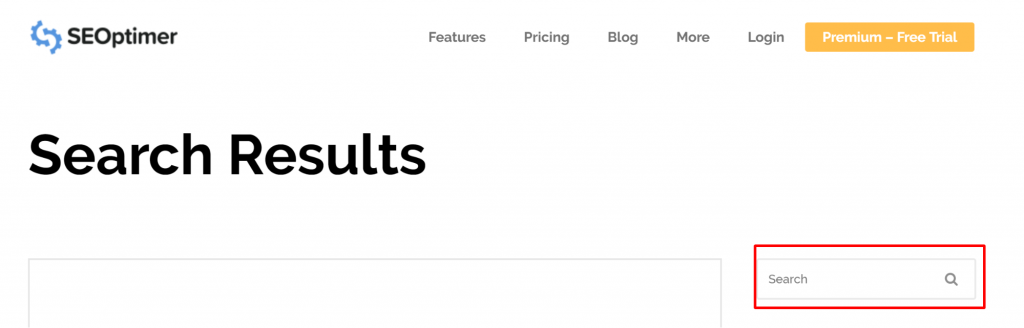
Nie ma to żadnego znaczenia, czy jest indeksowane, czy nie, ponieważ to nawet nie jest prawdziwy URL, ale zapytanie wyszukiwania. Alternatywnie, możesz usunąć stronę.
Strony, które powinny być indeksowane
Istnieje kilka powodów, dla których strony, które powinny być zaindeksowane, nie są indeksowane. Oto kilka z nich:
- Czy sprawdziłeś swoje dyrektywy robotów? Możesz mieć w swoim pliku robots.txt dyrektywy, które zabraniają indeksowania stron, które powinny być faktycznie indeksowane, na przykład tagów i kategorii. Tagi i kategorie to rzeczywiste adresy URL na Twojej stronie.
- Czy kierujesz Googlebot do łańcucha przekierowań? Googlebot przechodzi przez każdy link, na który natrafi i stara się go przeczytać do indeksacji. Jednakże, jeśli ustawisz wiele, długich, głębokich przekierowań, albo jeśli strona jest po prostu nieosiągalna, Googlebot przestanie szukać.
- Poprawnie zaimplementowano link kanoniczny? Tag kanoniczny jest używany w nagłówku HTML, aby poinformować Googlebot, która strona jest preferowana i kanoniczna w przypadku zduplikowanej treści. Każda strona powinna mieć tag kanoniczny. Na przykład, masz stronę, która jest przetłumaczona na język hiszpański. Powinieneś samoznaczyć kanonicznie hiszpański URL i chciałbyś kanonicznie przekierować stronę z powrotem do domyślnej wersji angielskiej.
Jak zweryfikować poprawność pliku Robots.txt w WordPress?
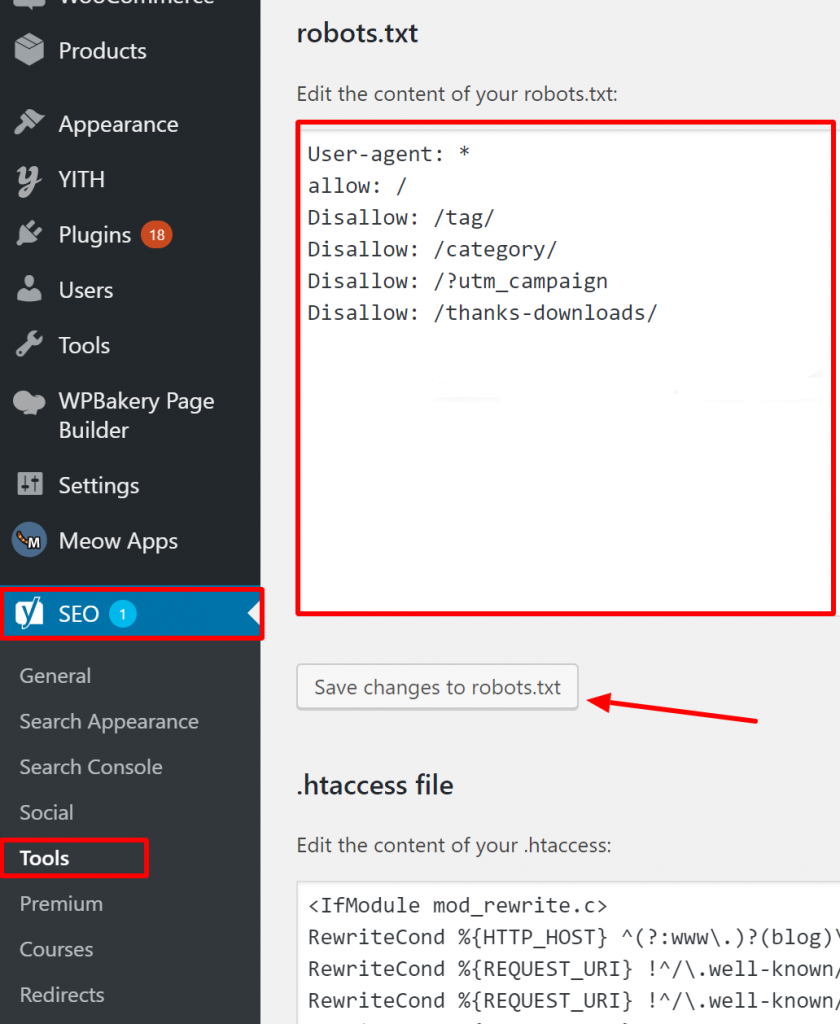
Dla WordPress, jeśli twój plik robots.txt jest częścią instalacji strony, użyj wtyczki Yoast do jego edycji. Jeśli plik robots.txt, który powoduje problemy, znajduje się na innej stronie, która nie jest twoją własnością, musisz skontaktować się z właścicielami tej strony i poprosić ich o edycję ich pliku robots.txt.
Strony, które nie powinny być indeksowane
Istnieje kilka powodów, dla których strony, które nie powinny być indeksowane, są indeksowane. Oto kilka z nich:
Dyrektywy Robots.txt, które "mówią", że strona nie powinna być indeksowana. Zauważ, że musisz zezwolić na przeszukiwanie strony z dyrektywą 'noindex', aby roboty wyszukiwarek "wiedziały", że nie powinna być indeksowana.
W twoim pliku robots.txt upewnij się, że:
- Linia ‘disallow’ nie następuje bezpośrednio po linii ‘user-agent’.
- Nie ma więcej niż jeden blok ‘user-agent’.
- Niewidoczne znaki Unicode - musisz przepuścić swój plik robots.txt przez edytor tekstu, który przekonwertuje kodowania. Spowoduje to usunięcie wszelkich specjalnych znaków.
Strony są linkowane z innych witryn. Strony mogą zostać zindeksowane, jeśli są linkowane z innych witryn, nawet jeśli są zabronione w robots.txt. W takim przypadku jednak w wynikach wyszukiwania pojawia się tylko adres URL i tekst kotwicy. Oto jak te adresy URL są wyświetlane na stronie wyników wyszukiwarki (SERP):
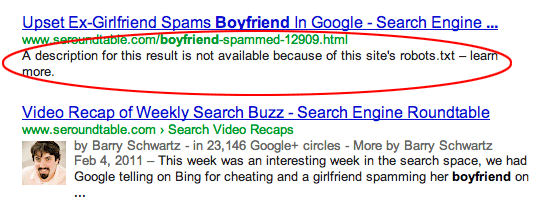 źródło obrazu Webmasters StackExchange
źródło obrazu Webmasters StackExchange
Jednym ze sposobów rozwiązania problemu blokowania przez robots.txt jest zabezpieczenie hasłem pliku(ów) na twoim serwerze.
Alternatywnie, usuń strony z pliku robots.txt lub użyj poniższego znacznika meta, aby zablokować
oni:
<meta name=”robots” content=”noindex”>
Stare adresy URL
Jeśli utworzyłeś nową treść lub nową stronę i użyłeś dyrektywy ‘noindex’ w robots.txt, aby upewnić się, że nie zostanie ona zindeksowana, lub niedawno zarejestrowałeś się w GSC, istnieją dwie opcje naprawienia problemu zablokowania przez robots.txt:
- Daj Google czas, aby ostatecznie usunąć stare adresy URL z indeksu
- Przekieruj stare adresy URL na obecne za pomocą przekierowania 301
W pierwszym przypadku, Google ostatecznie usuwa URL-e z indeksu, jeśli jedynym ich działaniem jest zwracanie 404 (co oznacza, że strony nie istnieją). Nie jest zalecane używanie wtyczek do przekierowywania twoich 404. Wtyczki mogą powodować problemy, które mogą doprowadzić do otrzymania ostrzeżenia od GSC o 'blokowaniu przez robots.txt'.
Wirtualne pliki robots.txt
Istnieje możliwość otrzymania powiadomienia nawet jeśli nie posiadasz pliku robots.txt. Wynika to z faktu, że strony oparte na CMS (Customer Management Systems), na przykład WordPress, posiadają wirtualne pliki robots.txt. Wtyczki mogą również zawierać pliki robots.txt. To one mogą być przyczyną problemów na Twojej stronie.
Te wirtualne pliki robots.txt muszą zostać nadpisane przez twój własny plik robots.txt. Upewnij się, że twój robots.txt zawiera dyrektywę pozwalającą wszystkim botom wyszukiwarek na indeksowanie twojej strony. Jest to jedyny sposób, aby mogły one określić, które adresy URL indeksować, a których nie.
Oto dyrektywa, która pozwala wszystkim botom indeksować Twoją stronę:
User-agent: *
Disallow: /
Oznacza to "nie zabraniaj niczego".
Podsumowując
Przyjrzeliśmy się ostrzeżeniu ‘Zaindeksowane, choć zablokowane przez robots.txt’, co ono oznacza, jak zidentyfikować dotknięte nim strony lub adresy URL, jak również przyczynę tego ostrzeżenia. Przyjrzeliśmy się także, jak to naprawić. Zauważ, że ostrzeżenie to nie jest równoznaczne z błędem na twojej stronie. Jednakże, nie naprawienie go może skutkować tym, że twoje najważniejsze strony nie zostaną zaindeksowane, co nie jest dobre dla doświadczenia użytkownika.