Robots.txtとは何ですか?
Robots.txtは、特定のページをインデックスに登録するかしないかをボットクローラーに指示するテキスト形式のファイルです。これは、あなたのサイト全体のゲートキーパーとしても知られています。ボットクローラーの最初の目的は、サイトマップやその他のページやフォルダにアクセスする前に、robots.txtファイルを見つけて読むことです。
robots.txtを使用して、より具体的に以下のことができます:
- 検索エンジンのボットがあなたのサイトをクロールする方法を規制する
- 特定のアクセスを提供する
- 検索エンジンのスパイダーがページのコンテンツをインデックスするのを助ける
- ユーザーにコンテンツを提供する方法を示す
Robots.txtは、サイト/ページ/URLレベルの指示を含むRobots Exclusion Protocol (R.E.P)の一部です。検索エンジンのボットは引き続きあなたのサイト全体をクロールすることができますが、特定のページが時間と労力の価値があるかどうかを決定するのを助けるのはあなた次第です。
Robots.txtが必要な理由
あなたのサイトは正しく機能するためにrobots.txtファイルが必要ではありません。robots.txtファイルが必要な主な理由は、ボットがあなたのページをクロールするときに、ページに関する情報をインデックスに取り込むためにクロールする許可を求めるためです。さらに、robots.txtファイルがないウェブサイトは、基本的にボットクローラーにサイトを好きなようにインデックスするように求めていることになります。ボットはrobots.txtファイルがなくてもあなたのサイトをクロールすることを理解することが重要です。
あなたのrobots.txtファイルの位置も重要です。なぜなら、すべてのボットはwww.123.com/robots.txtを探します。もし何も見つからなければ、サイトにはrobots.txtファイルがないと判断し、すべてをインデックスします。ファイルはASCIIまたはUTF-8のテキストファイルでなければなりません。また、ルールは大文字と小文字を区別することも重要です。
robots.txtが行うことと行わないことのいくつか:
- このファイルは、クローラーがウェブサイトの特定のエリアへのアクセスを制御することができます。robots.txtの設定を行う際には、ウェブサイト全体がインデックスされないようにブロックしてしまう可能性があるため、非常に注意が必要です。
- 重複するコンテンツがインデックスされて検索エンジンの結果に表示されるのを防ぎます。
- このファイルはクロール遅延を指定して、クローラーが同時に複数のコンテンツを読み込む際にサーバーが過負荷になるのを防ぎます。
時々あなたのサイトをクロールするかもしれないGooglebotのいくつかはこちらです:
| ウェブクローラー | "User-Agent String" |
| Googlebot ニュース | Googlebot-News |
| Googlebot 画像 | Googlebot-Image/1.0 |
| Googlebot ビデオ | Googlebot-Video/1.0 |
| Google Mobile(フィーチャーフォン) | SAMSUNG-SGH-E250/1.0 プロファイル/MIDP-2.0 コンフィギュレーション/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (互換性あり; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Google スマートフォン | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (互換性あり; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot(PPCランディングページの品質) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Googleアプリクローラー(モバイル用リソースをフェッチ) | AdsBot-Google-Mobile-Apps |
こちらで追加のボットのリストを見つけることができます。
- ファイルはサイトマップの位置の仕様を助けます。
- また、画像やPDFなどのウェブサイト上の様々なファイルのインデックスを検索エンジンボットが行うのを防ぎます。
ボットがあなたのウェブサイトを訪れたいと思った時(例えば、www.123.com)、最初にwww.123.com/robots.txtをチェックして、以下を見つけます:
User-agent: *
Disallow: /
この例は、すべての(User-agents*)検索エンジンボットに対して、ウェブサイトをインデックスしないよう指示します(Disallow: /)。
もしDisallowからスラッシュを取り除いたら、下記の例のようになります。
User-agent: *
Disallow:
ボットはウェブサイト上のすべてをクロールしてインデックスを作成することができます。これがrobots.txtの構文を理解することが重要である理由です。
robots.txtの構文を理解する
Robots.txtの構文は、robots.txtファイルの「言語」と考えることができます。robots.txtファイルでよく見かける用語は5つあります。それらは以下の通りです:
- User-agent: クロール指示を与えている特定のウェブクローラー(通常は検索エンジン)。ほとんどのユーザーエージェントのリストはこちらで見つけることができます。
- Disallow: ユーザーエージェントに特定のURLをクロールしないように指示するコマンド。各URLに対して"Disallow:"行は1つだけ許可されます。
- Allow(Googlebotにのみ適用):このコマンドは、親ページやサブフォルダが禁止されている場合でも、Googlebotがページやサブフォルダにアクセスできることを指示します。
- Crawl-delay: クローラーがページコンテンツを読み込んでクロールする前に待つべきミリ秒数です。Googlebotはこのコマンドを認識しないことに注意してくださいが、Google検索コンソールでクロールレートを設定できます。
- サイトマップ:URLに関連付けられたXMLサイトマップの場所を指定するために使用されます。このコマンドはGoogle、Ask、Bing、Yahooのみがサポートしています。
Robots.txtの指示結果
robots.txtの指示を出したとき、あなたは3つの結果を期待します:
- 完全許可
- 完全不許可
- 条件付き許可
完全許可
この結果は、ウェブサイト上のすべてのコンテンツがクロールされる可能性があることを意味します。Robots.txtファイルは、検索エンジンボットによるクローリングをブロックするためのものですので、このコマンドは非常に重要になることがあります。
この結果は、あなたのウェブサイトにrobots.txtファイルがまったくないことを意味する可能性があります。それがなくても、検索エンジンのボットはあなたのサイトでそれを探します。もし彼らがそれを見つけられなければ、彼らはあなたのウェブサイトのすべての部分をクロールします。
この結果の下の別のオプションは、robots.txtファイルを作成することですが、それを空のままにしておきます。クローラーが巡回に来たとき、robots.txtファイルを識別し、読み取ります。何も見つからないため、サイトの残りの部分のクロールを続けます。
もしrobots.txtファイルを持っていて、それに以下の二行が含まれている場合、
User-agent:*
Disallow:
検索エンジンのスパイダーはあなたのウェブサイトをクロールし、robots.txtファイルを特定して読み取ります。それは2行目に到達し、その後サイトの残りの部分をクロールし続けます。
完全な禁止
ここでは、コンテンツはクロールされず、インデックスされません。このコマンドは次の行によって発行されます:
User-agent:*
Disallow:/
コンテンツがないと言うとき、ウェブサイトの内容(コンテンツ、ページなど)がクロールされないことを意味します。これは決して良いアイデアではありません。
条件付き許可
これは、ウェブサイト上の特定のコンテンツのみがクロールされることを意味します。
条件付き許可は、この形式を持っています:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
ブロックされたページは、以下の画像に示すようにURLを禁止していても、まだインデックスされ得ることに注意してください:
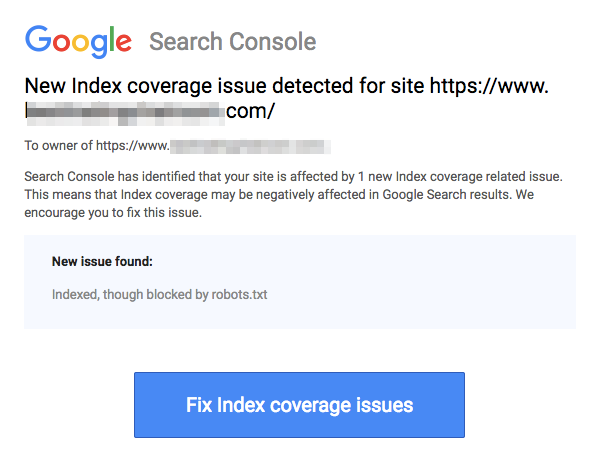
検索エンジンからあなたのURLがインデックスされたというメールを受け取るかもしれません。上のスクリーンショットのように。あなたが禁止したURLが他のサイトからリンクされている場合、例えばリンクのアンカーテキストで、それはインデックスされます。この解決策は、1) サーバー上のファイルにパスワード保護をかける、2) noindexメタタグを使用する、または3) ページを完全に削除することです。
ロボットはまだ私のrobots.txtファイルをスキャンして無視することができますか?
はい。ロボットがrobots.txtを回避することは可能です。これは、Googleが外部情報や受信リンクなどの他の要因を使用して、ページがインデックスされるべきかどうかを判断するためです。ページをまったくインデックスさせたくない場合は、noindexロボットメタタグを利用するべきです。別のオプションとしては、X-Robots-Tag HTTPヘッダーを使用することができます。
悪質なロボットだけをブロックできますか?
理論的には悪質なロボットをブロックすることは可能ですが、実際に行うのは難しいかもしれません。いくつかの方法を見てみましょう:
- 悪質なロボットは、それを除外することでブロックすることができます。しかし、その特定のロボットがUser-Agentフィールドでスキャンする名前を知る必要があります。その後、robots.txtファイルに悪質なロボットを除外するセクションを追加する必要があります。
- サーバー設定。これは悪意のあるロボットの操作が単一のIPアドレスからのものである場合にのみ機能します。サーバー設定またはネットワークファイアウォールが、悪意のあるロボットがあなたのウェブサーバーにアクセスするのをブロックします。
- 高度なファイアウォールルールの設定を使用します。これにより、悪質なロボットのコピーが存在するさまざまなIPアドレスへのアクセスが自動的にブロックされます。さまざまなIPアドレスで動作するボットの良い例は、より大きなボットネットの一部である可能性がある乗っ取られたPCの場合です(ボットネットについてこちらで詳しく学びましょう)。
もし悪質なロボットが単一のIPアドレスから操作している場合、サーバーの設定やネットワークファイアウォールを通じて、そのアクセスをウェブサーバーからブロックすることができます。
もしロボットのコピーが様々なIPアドレスで動作している場合、それらをブロックすることはより困難になります。この場合の最良の選択肢は、多くの接続を行うIPアドレスへのアクセスを自動的にブロックする高度なファイアウォールルールの設定を使用することです。残念ながら、これは良いボットのアクセスにも影響を与える可能性があります。
robots.txtを使用する際の最良のSEO実践方法は何ですか?
この時点で、あなたはこれらの非常に厄介なrobots.txtの水域をどのように航行するか疑問に思っているかもしれません。これをもっと詳しく見ていきましょう:
- クロールしてほしいサイトのコンテンツやセクションをブロックしていないことを確認してください。
- robots.txt以外のブロッキングメカニズムを使用して、robots.txtで実質的にブロックされているページからリンク先にリンクエクイティを渡したい場合。
- 検索エンジンの結果にプライベートなユーザー情報などの機密データが表示されないようにするためにrobots.txtを使用しないでください。そうすると、プライベートなユーザー情報を含むページへリンクする他のページが存在する可能性があり、そのページがインデックスされるかもしれません。この場合、robots.txtは迂回されています。ここで検討できる他のオプションには、パスワード保護やnoindexのメタディレクティブがあります。
- 検索エンジンのクローラーごとに指示を指定する必要はありません。なぜなら、ほとんどのユーザーエージェントは、同じ検索エンジンに属している場合、同じルールに従うからです。Googleは検索エンジン用にGooglebotを、画像検索用にGooglebot Imageを使用しています。各クローラーを指定する方法を知る唯一の利点は、サイト上のコンテンツがどのようにクロールされるかを正確に微調整できることです。
- robots.txtファイルを変更した場合、Googleにより早く更新してもらいたいなら、直接Googleに送信してください。その方法については、こちらをクリックしてください。検索エンジンはrobots.txtの内容をキャッシュし、キャッシュされた内容を少なくとも1日に1回は更新することに注意が必要です。
基本的なrobots.txtのガイドライン
あなたがrobots.txtに関連するSEOの基本的な理解を持っている今、robots.txtを使用する際に心に留めておくべきことは何でしょうか?このセクションでは、robots.txtを使用する際に従うべきいくつかのガイドラインを見ていきますが、全ての構文を実際に読むことが重要です。
フォーマットと位置
robots.txtファイルを作成するために使用するテキストエディタは、標準のASCIIまたはUTF-8テキストファイルを作成できる必要があります。ワードプロセッサの使用は良い考えではありません。なぜなら、クローリングに影響を与える可能性のある文字が追加されるかもしれないからです。
ほとんどのテキストエディタを使用してrobots.txtファイルを作成することができますが、このツールはあなたのサイトに対してテストを行うことができるため、非常に推奨されています。
形式と場所に関するさらなるガイドラインはこちらです:
- 作成するファイルの名前を「robots.txt」とする必要があります。なぜなら、ファイル名は大文字と小文字が区別されるからです。大文字は使用しません。
- サイト全体で一つのrobots.txtファイルしか持つことができません。
- robots.txtファイルは一か所にのみ存在します:それが適用されるウェブサイトホストのルートです。サブディレクトリに配置することはできないことに注意してください。もし貴方のウェブサイトがhttp://www.123.com/、その場合のrobots.txtの場所はhttp://www.123.com/robots.txt、ではないhttp://www.123.com/pages/robots.txt. robots.txt ファイルはサブドメインにも適用されることに注意してください (http://website.123.com/robots.txt) そして非標準のポートも含めて、例えばhttp://www.123.com: 8181/robots.txt.
前述の通り、robots.txtは機密個人情報がインデックスされるのを防ぐ最良の方法ではありません。これは、特に最近実施されたGDPRを考えると、正当な懸念です。データプライバシーは妥協されるべきではありません。絶対に。
robots.txtが検索結果に機密データを表示しないようにするにはどうすればよいですか?
ウェブ上で「リスト化不可能」な別のサブディレクトリを使用することで、機密資料の配布を防ぐことができます。サーバー設定を使用して、それが「リスト化不可能」であることを確認できます。robots.txtが訪問してインデックスを作成したくないすべてのファイルをこのサブディレクトリに保存してください。
robots.txtファイルにページやディレクトリをリストすることは、意図しないアクセスを招く結果になりませんか?
前述の通り、インデックスされたくないファイルを別のサブディレクトリに置き、サーバーの設定でリスト化不可にすることで、検索結果に表示されないようにすることができます。その後、robots.txtファイルでリストするのはディレクトリ名のみです。これらのファイルにアクセスする唯一の方法は、ファイルへの直接リンクを通じてです。
こちらが一例です:
代わりに
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
使用する
User-Agent:*
Disallow:/norobots/
次に、「norobots」ディレクトリを作成する必要があります。これにはfoo.htmlとbar.htmlが含まれます。サーバーの設定で「norobots」ディレクトリのディレクトリリストを生成しないように明確にする必要があることに注意してください。
これはあまり安全なアプローチではないかもしれません。なぜなら、あなたのサイトを攻撃している人やボットは、ディレクトリ内のファイルを見ることができないかもしれませんが、「norobots」ディレクトリが存在することを依然として確認できるからです。しかし、誰かがそのファイルへのリンクを自分のウェブサイトに公開するか、さらに悪いことに、そのリンクが公開されているログファイル(例えば、リファラとしてのウェブサーバーログ)に表示される可能性があります。サーバーの設定ミスもあり得ます。その結果、ディレクトリリストが表示されることになります。
これはどういう意味ですか?Robots.txtはアクセス制御に役立ちません。それはそのために意図されていないからです。「立入禁止」の標識が良い例です。指示に違反する人がまだいます。
認証された人々にのみアクセスしてほしいファイルがある場合、サーバーの設定が認証を助けます。CMS(コンテンツ管理システム)を使用している場合、個々のページやリソースコレクションにアクセス制御があります。
robots.txtをSEOに最適化できますか?
もちろんです。robots.txtを最適化するための最良のガイドはサイトコンテンツです。簡単なリマインダー:Robots.txtは、検索エンジンボットによるページのクロールをブロックするためには決して使用されるべきではありません。公開されていないウェブサイトのセクション、例えばwp-adminのようなログインページをブロックするためにのみ使用してください。
これは、彼のウェブサイトの1つにおけるNeil Patelのログインページのdisallow行です:
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
このdisallow行を使用して、ログインがインデックスされるのをブロックできます。
インデックスを作成したくない特定のページがある場合は、上記と同じコマンドを使用してください。例:
User-agent:*
Disallow:/page/
スラッシュの後にインデックスを付けたくないページを指定し、別のスラッシュで閉じます。例えば:
User-agent:*
Disallow:/page/thank-you/
インデックスから除外したいページにはどのようなものがありますか?
- 意図的な重複コンテンツとは何か。これはどういう意味か?時には特定の目的を達成するために意図的に重複コンテンツを作成することがあります。良い例は、特定のウェブページのプリンター向けバージョンです。robots.txtを使用して、同一コンテンツのプリンター向けバージョンのインデックスをブロックすることができます。
- 「サンキューページ」。このページのインデックスをブロックしたい理由は単純です。これは販売ファネルの最終ステップであるべきです。訪問者がこのページに到達する頃には、すでに販売ファネル全体を通過しているはずです。このページがインデックスされると、リードを逃す可能性があるか、または偽のリードを受け取ることになるかもしれません。
そのようなページをブロックするコマンドは以下の通りです:
Disallow:/thank-you/
NoindexとNoFollow
この記事を通じて私たちが言ってきたように、robots.txtを使用してもページがインデックスされないという100%の保証はありません。ブロックされたページが確かにインデックスされないことを保証する2つの方法を見てみましょう。
noindexディレクティブ
これはdisallowコマンドと連携して動作します。以下のように、ディレクティブで両方を使用してください:
Disallow:/thank-you/
nofollowディレクティブ
これは、Googleボットがページ上のリンクをクロールしないように特別に指示するためのものです。これはrobots.txtファイルの一部ではありません。nofollowコマンドを使用してページがクロールおよびインデックスされるのをブロックするには、インデックスされたくない特定のページのソースコードを見つける必要があります。
開始タグと終了タグのheadタグの間にこれを貼り付けてください:
<meta name = "robots" content="nofollow">
「nofollow」と「noindex」を同時に使用することができます。このコード行を使用してください:
<meta name = "robots" content="noindex,nofollow">
robots.txtの生成
もしrobots.txtを書くのが難しく、理解して従う必要があるすべての必要なフォーマットや構文を使用することが難しい場合、プロセスを簡素化するツールを使用することができます。良い例は、私たちの無料のrobots.txtジェネレーターです。
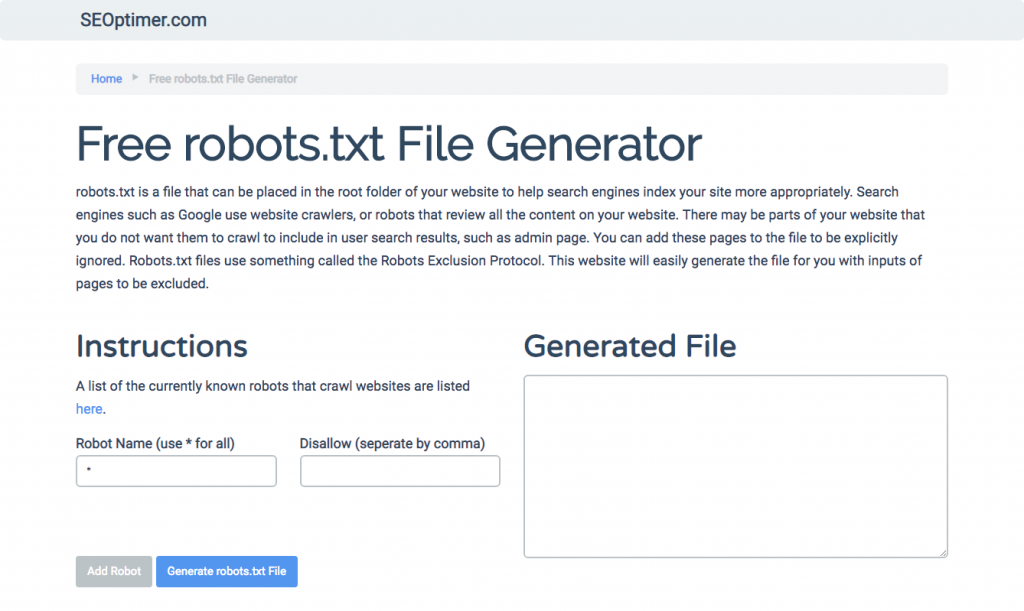
このツールを使用すると、ウェブサイトで必要な結果のタイプを選択し、追加したいファイルやディレクトリを指定できます。ファイルをテストして、競合他社の状況を確認することもできます。
robots.txtファイルのテスト
robots.txtファイルが期待通りに動作しているかテストする必要があります。
Googleのrobots.txtテスターを使用してください。
これを行うには、Webmaster’sアカウントにサインインしてください。
- 次に、あなたのプロパティを選択してください。この場合、それはあなたのウェブサイトです。
- 左側のサイドバーで「クロール」をクリックします。
- 「robots.txt テスター」をクリックします。
- 既存のコードを新しい robots.txt ファイルで置き換えてください。
- 「テスト」をクリックします。
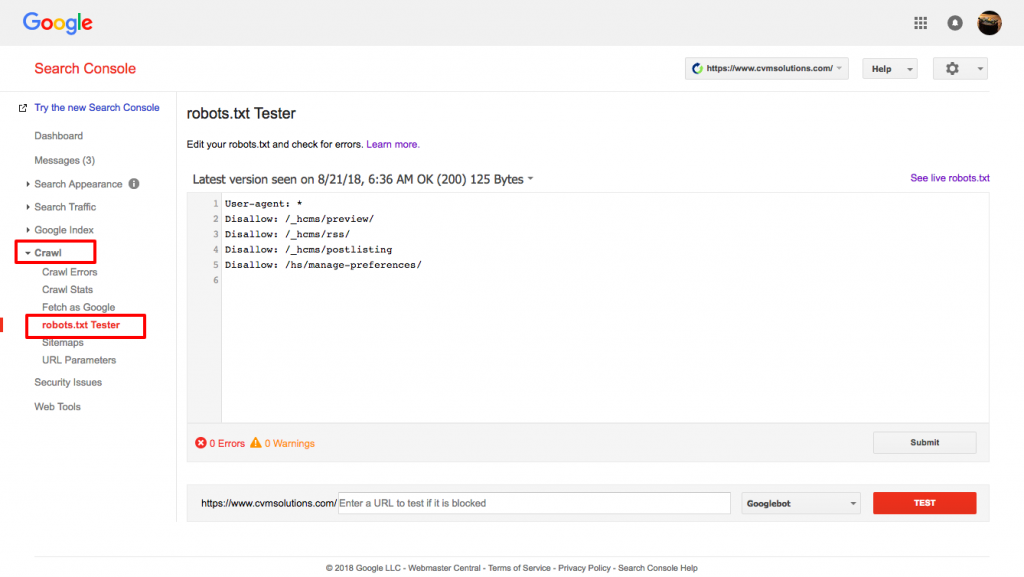
ファイルが有効であれば、テキストボックス「allowed」が表示されるはずです。詳細については、Google robots.txt testerの詳細ガイドをご覧ください。
もしファイルが有効であれば、それをルートディレクトリにアップロードするか、または他のrobots.txtファイルがある場合は保存する時です。
WordPressサイトにrobots.txtを追加する方法
WordPressファイルにrobots.txtファイルを追加する方法として、プラグインとFTPのオプションについて説明します。
プラグインオプションには、All in One SEO Packのようなプラグインを使用できます
これを行うには、WordPressのダッシュボードにログインしてください
「プラグイン」までスクロールダウンしてください
「新規追加」をクリックしてください
「検索プラグイン」へ行ってください
「All in One SEO Pack」と入力してください
インストールして、アクティベートしてください
All in One SEOプラグインの一般設定セクションでは、robots.txtファイルに含めるためのnoindexおよびnofollowルールを設定できます。
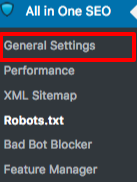
どのURLをNOINDEX、NOFOLLOWにすべきか指定することができます。これらをチェックしない場合は、デフォルトでインデックスされます:
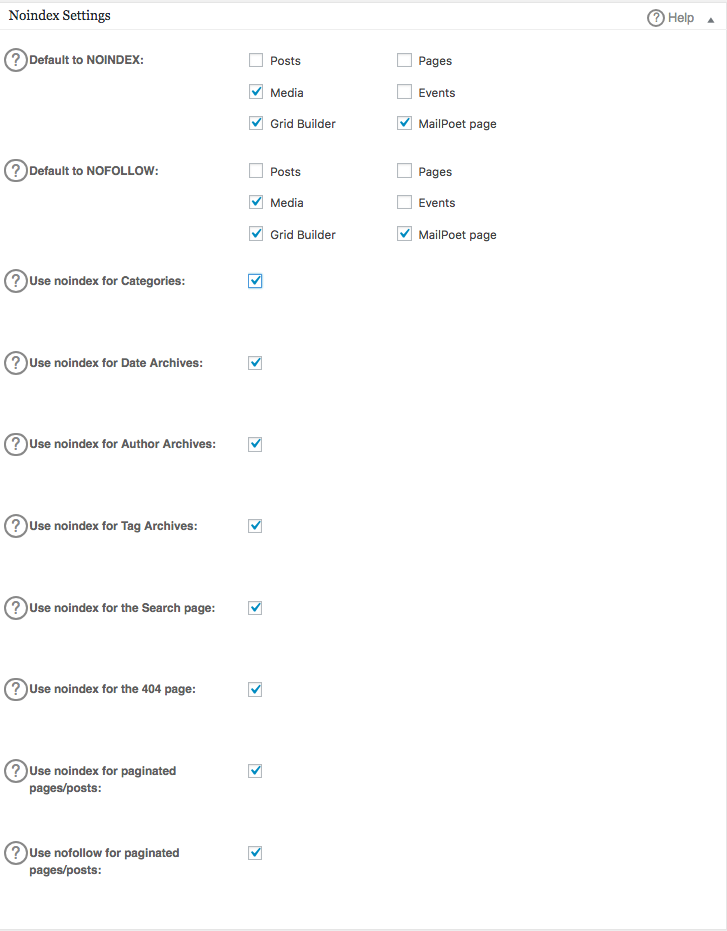
robots.txtファイルで高度なルールを作成するには、フィーチャーマネージャーをクリックし、その下にあるアクティベートボタンをクリックしてください。
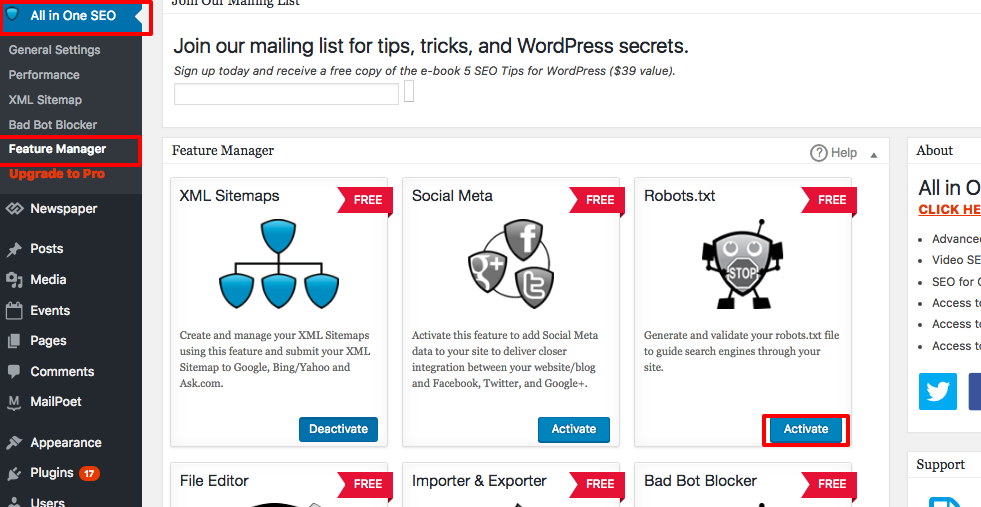
Robots.txtは現在、フィーチャーマネージャーのすぐ下に表示されます。それをクリックしてください。そうすると、「robots.txtファイルを作成する」というセクションが表示されます。
ルールビルダーセクションがあり、インデックスを付けたくないものに応じて、サイトに適用したいルールを選択して記入することができます。
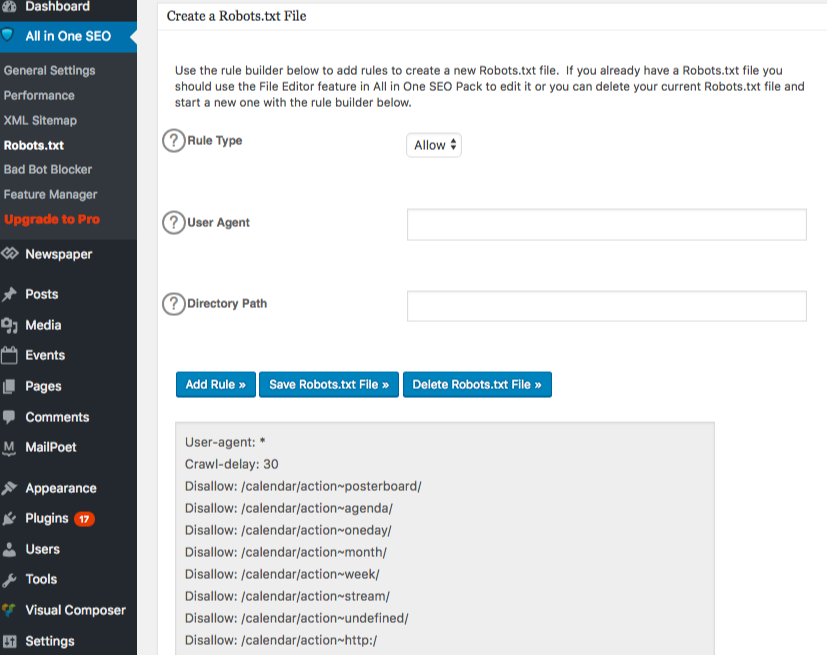
ルールの作成が完了したら、「ルールを追加」をクリックしてください。
そのルールは、作成されたrobots.txtフォルダーの下にリストされます。
「All in One Options」が更新されたことを示すメッセージが表示されます。
もう一つの方法は、robots.txtファイルをFileZillaのようなFTP(File Transfer Protocol)クライアントに直接アップロードすることです。
robots.txtファイルを生成したら、そのファイルを見つけて置き換えることができます。robots.txtファイルは次の場所にあります:「/applications/[フォルダ名]/public_html。」
Wixでrobots.txtファイルを編集する方法
Wixは、ウェブビルディングプラットフォームを使用しているウェブサイトのためにrobots.txtファイルを生成します。それを表示するには、ドメインに「/robots.txt」を追加してください。robots.txtに追加されたファイルは、例えばnoflashhtmlリンクのように、Wixで構築されたサイトのSEO価値に貢献しないWixサイトの構造に関係しています。
あなたのサイトがWixによって運営されている場合、robots.txtファイルを編集することはできません。インデックスされたくないページに「noindexタグ」を追加するなど、他のオプションを使用することしかできません。
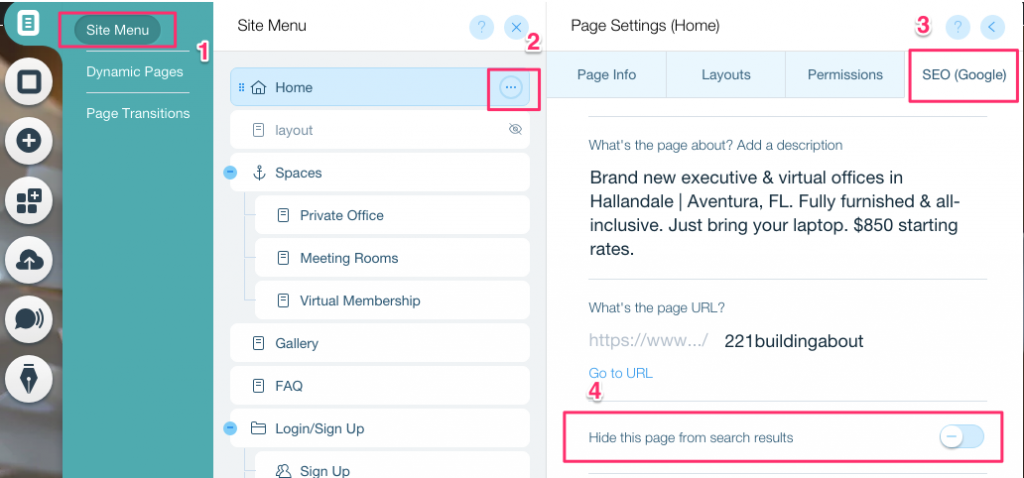
特定のページにnoindexタグを作成するには:
- サイトメニューをクリックしてください
- その特定のページの設定オプションをクリックしてください
- SEO (Google) タグを選択してください
- このページを検索結果から隠すをオンにしてください
Shopifyでrobots.txtファイルを編集する方法
Wixと同様に、Shopifyは自動的に編集不可能なrobots.txtファイルをあなたのサイトに追加します。一部のページをインデックスに追加したくない場合は、「noindexタグ」を追加するか、ページの公開を取り消す必要があります。インデックスに追加したくないページのヘッダーセクションにメタタグを追加することもできます。これがあなたのヘッダーに追加すべき内容です:
<meta name= “robots” content = “noindex”>
Shopifyは、検索エンジンからページを隠す方法について詳細なガイドを作成しました。
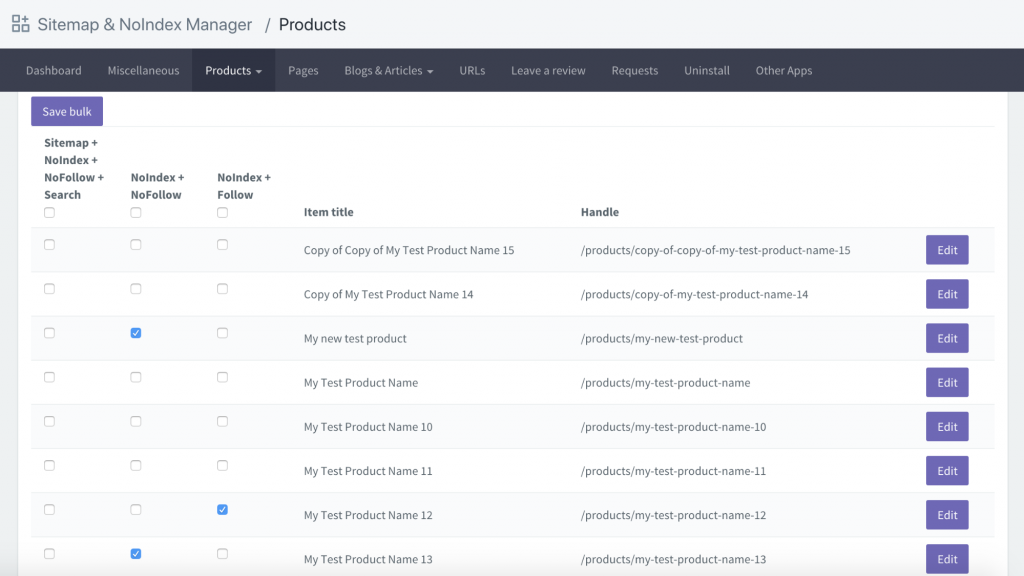
別のオプションは、Sitemap & NoIndex Manager というアプリをダウンロードすることです。Orbis Labsによって提供されています。Shopifyサイトの各ページに対して、noindexまたはnofollowオプションを単にチェックすることができます: