Cos'è Robots.txt?
Robots.txt è un file in formato testo che istruisce i bot crawler ad indicizzare o non indicizzare certe pagine. È anche conosciuto come il custode per l'intero sito. Il primo obiettivo dei bot crawler è trovare e leggere il file robots.txt, prima di accedere alla tua sitemap o a qualsiasi pagina o cartella.
Con robots.txt, puoi più specificamente:
- Regola il modo in cui i bot dei motori di ricerca esplorano il tuo sito
- Fornisci un certo accesso
- Aiuta i spider dei motori di ricerca ad indicizzare il contenuto della pagina
- Mostra come servire il contenuto agli utenti
Robots.txt è una parte del Protocollo di Esclusione dei Robot (R.E.P), che comprende le direttive a livello di sito/pagina/URL. Anche se i bot dei motori di ricerca possono ancora esplorare l'intero sito, spetta a te aiutarli a decidere se certe pagine valgono il tempo e lo sforzo.
Perché hai bisogno di Robots.txt
Il tuo sito non ha bisogno di un file robots.txt affinché funzioni correttamente. I principali motivi per cui hai bisogno di un file robots.txt sono affinché, quando i bot esplorano la tua pagina, chiedano il permesso di esplorare per poter tentare di recuperare informazioni sulla pagina da indicizzare. Inoltre, un sito web senza un file robots.txt sta fondamentalmente invitando i bot crawler ad indicizzare il sito come ritengono opportuno. È importante comprendere che i bot esploreranno comunque il tuo sito senza il file robots.txt.
La posizione del tuo file robots.txt è importante perché tutti i bot cercheranno www.123.com/robots.txt. Se non trovano nulla lì, assumeranno che il sito non abbia un file robots.txt e indicizzeranno tutto. Il file deve essere un file di testo ASCII o UTF-8. È anche importante notare che le regole sono sensibili al maiuscolo/minuscolo.
Ecco alcune cose che robots.txt farà e non farà:
- Il file è in grado di controllare l'accesso dei crawler a determinate aree del tuo sito web. Devi essere molto attento quando configuri robots.txt poiché è possibile bloccare l'intero sito web dall'essere indicizzato.
- Impedisce che contenuti duplicati vengano indicizzati e appaiano nei risultati dei motori di ricerca.
- Il file specifica il ritardo di scansione al fine di prevenire il sovraccarico dei server quando i crawler stanno caricando più pezzi di contenuto contemporaneamente.
Ecco alcuni Googlebots che potrebbero navigare sul tuo sito di tanto in tanto:
| Web Crawler | Stringa User-Agent |
| Notizie Googlebot | Googlebot-News |
| Googlebot Immagini | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (telefono di fascia bassa) | SAMSUNG-SGH-E250/1.0 Profile/MIDP-2.0 Configuration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (compatibile; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Smartphone Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, come Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatibile; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (compatibile; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (qualità della pagina di destinazione PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app crawler (recupera risorse per dispositivi mobili) | AdsBot-Google-Mobile-Apps |
Puoi trovare un elenco di ulteriori bot qui.
- I file aiutano nella specifica della posizione delle sitemap.
- Impedisce anche ai bot dei motori di ricerca di indicizzare vari file sul sito web come immagini e PDF.
Quando un bot vuole visitare il tuo sito web (per esempio, www.123.com), inizialmente verifica la presenza di www.123.com/robots.txt e trova:
User-agent: *
Disallow: /
Questo esempio istruisce tutti i (User-agents*) bot dei motori di ricerca a non indicizzare (Disallow: /) il sito web.
Se rimuovi la barra obliqua da Disallow, come nell'esempio qui sotto,
User-agent: *
Disallow:
i bot sarebbero in grado di esplorare e indicizzare tutto sul sito web. Ecco perché è importante comprendere la sintassi di robots.txt.
Comprensione della sintassi di robots.txt
La sintassi di Robots.txt può essere considerata come il "linguaggio" dei file robots.txt. Ci sono 5 termini comuni che è probabile incontrare in un file robots.txt. Essi sono:
- User-agent: Il crawler web specifico al quale stai fornendo istruzioni di scansione (solitamente un motore di ricerca). Un elenco della maggior parte degli user agents può essere trovato qui.
- Disallow: Il comando utilizzato per dire a un user agent di non esplorare un particolare URL. È consentita solo una riga "Disallow:" per ogni URL.
- Allow (Applicabile solo per Googlebot): Il comando indica a Googlebot che può accedere a una pagina o sottocartella anche se la pagina o sottocartella genitore potrebbe essere vietata.
- Crawl-delay: Il numero di millisecondi che un crawler dovrebbe attendere prima di caricare e analizzare il contenuto di una pagina. Nota che Googlebot non riconosce questo comando, ma la frequenza di scansione può essere impostata in Google Search Console.
- Mappa del sito: Utilizzato per indicare la posizione di qualsiasi mappa del sito XML associata a un URL. Nota che questo comando è supportato solo da Google, Ask, Bing e Yahoo.
Esiti delle istruzioni Robots.txt
Quando emetti istruzioni robots.txt ti aspetti tre risultati:
- Consentimento completo
- Divieto completo
- Consentimento condizionato
Esaminiamo ciascuno di seguito.
Consentimento completo
Questo risultato significa che tutto il contenuto sul tuo sito web può essere esplorato. I file robots.txt sono destinati a bloccare l'esplorazione da parte dei bot dei motori di ricerca, quindi questo comando può essere molto importante.
Questo risultato potrebbe significare che non hai affatto un file robots.txt sul tuo sito web. Anche se non lo hai, i bot dei motori di ricerca lo cercheranno comunque sul tuo sito. Se non lo trovano, allora esploreranno tutte le parti del tuo sito web.
L'altra opzione sotto questo risultato è di creare un file robots.txt ma lasciarlo vuoto. Quando il ragno viene a esplorare, identificherà e persino leggerà il file robots.txt. Poiché non troverà nulla lì, procederà ad esplorare il resto del sito.
Se hai un file robots.txt e contiene le seguenti due righe,
User-agent:*
Disallow:
il motore di ricerca spider esaminerà il tuo sito web, identificherà il file robots.txt e lo leggerà. Arriverà alla seconda riga e poi procederà ad esaminare il resto del sito.
Divieto completo
Qui, nessun contenuto verrà esplorato e indicizzato. Questo comando viene emesso da questa riga:
User-agent:*
Disallow:/
Quando parliamo di nessun contenuto, intendiamo che nulla del sito web (contenuti, pagine, ecc.) può essere esplorato. Questa non è mai una buona idea.
Permessi Condizionali
Questo significa che solo determinati contenuti sul sito web possono essere esplorati.
Un permesso condizionale ha questo formato:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
Puoi trovare la sintassi completa di robots.txt qui.
Nota che le pagine bloccate possono comunque essere indicizzate anche se hai disabilitato l'URL come mostrato nell'immagine qui sotto:
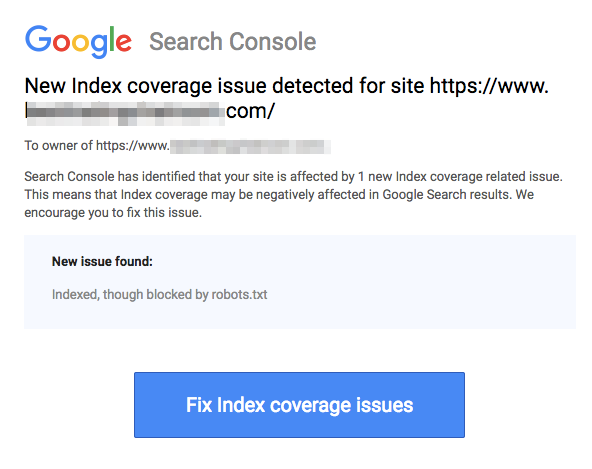
Potresti ricevere un'email dai motori di ricerca che indica che il tuo URL è stato indicizzato come nello screenshot sopra. Se il tuo URL disabilitato è collegato da altri siti, come testo di ancoraggio nei link, verrà indicizzato. La soluzione a questo è 1) proteggere con password i tuoi file sul server, 2) utilizzare il meta tag noindex, o 3) rimuovere completamente la pagina.
Un robot può ancora scansionare e ignorare il mio file robots.txt?
Sì. è possibile che un robot possa ignorare robots.txt. Questo perché Google utilizza altri fattori come informazioni esterne e link in entrata per determinare se una pagina dovrebbe essere indicizzata o meno. Se non vuoi che una pagina venga indicizzata affatto, dovresti utilizzare il meta tag robots noindex. Un'altra opzione sarebbe quella di utilizzare l'intestazione HTTP X-Robots-Tag.
Posso bloccare solo i robot cattivi?
È possibile bloccare i robot dannosi in teoria, ma potrebbe essere difficile farlo nella pratica. Vediamo alcuni modi per farlo:
- Puoi bloccare un cattivo robot escludendolo. Devi però conoscere il nome con cui il particolare robot effettua la scansione nel campo User-Agent. Dovrai quindi aggiungere una sezione nel tuo file robots.txt che escluda il cattivo robot.
- Configurazione del server. Questo funzionerebbe solo se l'operazione del cattivo robot proviene da un singolo indirizzo IP. La configurazione del server o un firewall di rete bloccherà il cattivo robot dall'accesso al tuo server web.
- Utilizzo di configurazioni avanzate delle regole del firewall. Queste bloccheranno automaticamente l'accesso ai vari indirizzi IP dove esistono copie del cattivo robot. Un buon esempio di bot che operano in vari indirizzi IP è nel caso di PC dirottati che potrebbero anche far parte di un Botnet più grande (per saperne di più su Botnet qui).
Se il cattivo robot opera da un singolo indirizzo IP, puoi bloccare il suo accesso al tuo server web tramite la configurazione del server o con un firewall di rete.
Se delle copie del robot operano su un numero di indirizzi IP diversi, allora diventa più difficile bloccarli. La migliore opzione in questo caso è utilizzare configurazioni avanzate delle regole del firewall che bloccano automaticamente l'accesso agli indirizzi IP che effettuano molte connessioni; sfortunatamente, questo potrebbe influenzare anche l'accesso dei bot buoni.
Quali sono alcune delle migliori pratiche SEO quando si utilizza robots.txt?
A questo punto, potresti chiederti come navigare in queste acque molto insidiose dei robots.txt. Vediamolo più nel dettaglio:
- Assicurati di non bloccare nessun contenuto o sezione del tuo sito che desideri venga esplorato.
- Utilizza un meccanismo di blocco diverso da robots.txt se vuoi che l'equità dei link venga passata da una pagina con robots.txt (il che significa che è praticamente bloccata) alla destinazione del link.
- Non utilizzare robots.txt per impedire che dati sensibili, come informazioni private degli utenti, appaiano nei risultati dei motori di ricerca. Fare ciò potrebbe permettere ad altre pagine di collegarsi a pagine che contengono informazioni private degli utenti, il che potrebbe causare l'indicizzazione della pagina. In questo caso, robots.txt è stato bypassato. Altre opzioni che potresti esplorare qui sono la protezione con password o la direttiva meta noindex.
- Non c'è bisogno di specificare direttive per ciascuno dei crawler di un motore di ricerca poiché la maggior parte degli user agents, se appartengono allo stesso motore di ricerca, seguono le stesse regole. Google utilizza Googlebot per i motori di ricerca e Googlebot Image per le ricerche di immagini. L'unico vantaggio nel sapere come specificare ciascun crawler è che sei in grado di regolare esattamente come i contenuti del tuo sito vengono esplorati.
- Se hai modificato il file robots.txt e vuoi che Google lo aggiorni più velocemente, invialo direttamente a Google. Per istruzioni su come fare, clicca qui. È importante notare che i motori di ricerca memorizzano nella cache il contenuto di robots.txt e aggiornano il contenuto memorizzato nella cache almeno una volta al giorno.
Linee guida di base per robots.txt
Ora che hai una conoscenza di base della SEO in relazione a robots.txt, quali cose dovresti tenere a mente quando utilizzi robots.txt? In questa sezione, esaminiamo alcune linee guida da seguire quando si utilizza robots.txt, anche se è importante leggere effettivamente l'intera sintassi.
Formato e posizione
L'editor di testo che scegli di utilizzare per creare un file robots.txt deve essere in grado di creare file di testo standard ASCII o UTF-8. Utilizzare un elaboratore di testi non è una buona idea poiché potrebbero essere aggiunti alcuni caratteri che possono influenzare la scansione.
Mentre quasi ogni editor di testo può essere utilizzato per creare il tuo file robots.txt, questo strumento è altamente raccomandato in quanto permette di effettuare test sul tuo sito.
Ecco altre linee guida su formato e posizione:
- Devi nominare il file che crei "robots.txt" perché il nome del file è case sensitive. Non si utilizzano caratteri maiuscoli.
- Puoi avere solo un file robots.txt su tutto il sito.
- Il file robots.txt si trova soltanto in un posto: la radice dell'host del sito web a cui è applicabile. Nota che non può essere posizionato in una sottodirectory. Se il tuo sito web èhttp://www.123.com/, quindi la posizione di robots.txt è http://www.123.com/robots.txt, non http://www.123.com/pages/robots.txt. Si noti che il file robots.txt può essere applicato ai sottodomini (http://website.123.com/robots.txt) e persino porte non standard, come http://www.123.com: 8181/robots.txtSe il testo da tradurre è solo un punto ".", allora non c'è nulla da tradurre in italiano. Il punto rimane invariato in tutte le lingue.
Come precedentemente menzionato, robots.txt non è il modo migliore per impedire che le informazioni personali sensibili vengano indicizzate. Questa è una preoccupazione valida, specialmente ora con il recentemente implementato GDPR. La privacy dei dati non dovrebbe essere compromessa. Punto.
Come si fa quindi a garantire che robots.txt non mostri dati sensibili nei risultati di ricerca?
Utilizzare una sottodirectory separata che sia "non elencabile" sul web impedirà la distribuzione di materiale sensibile. Puoi assicurarti che sia "non elencabile" utilizzando la configurazione del server. Semplicemente archivia tutti i file che non vuoi che robots.txt visiti e indicizzi in questa sottodirectory.
Elencare pagine o directory nel file robots.txt può risultare in accessi non intenzionali?
Come precedentemente menzionato, mettere tutti i file che non si desidera vengano indicizzati in una sottocartella separata e poi renderla non elencabile tramite configurazioni del server dovrebbe garantire che non compaiano nei risultati di ricerca. L'unica elencazione che si farà poi nel file robots.txt è il nome della directory. L'unico modo per accedere a questi file è tramite un link diretto a uno dei file.
Ecco un esempio:
Invece di
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Usa
User-Agent:*
Disallow:/norobots/
Quindi devi creare una directory "norobots", che include foo.html e bar.html. Nota che le configurazioni del tuo server devono essere chiare riguardo al non generare un elenco di directory per la directory "norobots".
Questo potrebbe non essere un approccio molto sicuro perché la persona o il bot che attacca il tuo sito può comunque vedere che hai una directory "norobots" anche se potrebbero non essere in grado di visualizzare i file all'interno della directory. Tuttavia, qualcuno potrebbe pubblicare un link a quei file sul proprio sito web o, peggio ancora, il link potrebbe apparire in un file di log accessibile al pubblico (ad esempio un log del server web come referrer). È anche possibile una cattiva configurazione del server, che risulta in un elenco di directory.
Che cosa significa questo? Robots.txt non può aiutarti a controllare l'accesso per il semplice motivo che non è stato creato per questo. Un buon esempio è un "cartello di divieto di accesso". Ci sono persone che violeranno comunque l'istruzione.
Se ci sono file che vuoi siano accessibili solo da persone autorizzate, le configurazioni del server aiuteranno con l'autenticazione. Se utilizzi un CMS (Content Management System), hai controlli di accesso su pagine individuali e raccolte di risorse.
Puoi ottimizzare il file robots.txt per il SEO?
Assolutamente. La migliore guida su come ottimizzare robots.txt è il contenuto del sito. Un rapido promemoria: Robots.txt non dovrebbe mai essere utilizzato per bloccare le pagine dall'essere esplorate dai bot dei motori di ricerca. Usalo solo per bloccare le sezioni del tuo sito web non accessibili al pubblico, ad esempio, pagine di login come wp-admin.
Questa è la linea di disallow per la pagina di login di Neil Patel su uno dei suoi siti web:
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
Puoi utilizzare questa linea di disallow per impedire che il tuo login venga indicizzato.
Se ci sono alcune pagine specifiche che non vuoi vengano indicizzate, usa lo stesso comando di sopra. Un esempio:
User-agent:*
Disallow:/page/
Specifica la pagina che non vuoi venga indicizzata dopo la barra e chiudi con un'altra barra. Ad esempio:
User-agent:*
Disallow:/page/grazie/
Quali sono alcune delle pagine che potresti voler escludere dall'essere indicizzate?
- Contenuto duplicato che è intenzionale. Cosa significa questo? A volte si crea intenzionalmente contenuto duplicato per raggiungere uno scopo particolare. Un buon esempio è una versione della pagina web adatta alla stampa. Si può utilizzare robots.txt per bloccare l'indicizzazione della versione adatta alla stampa del contenuto identico.
- Pagine di ringraziamento. Il motivo per cui si desidera bloccare l'indicizzazione di questa pagina è semplice: dovrebbe essere l'ultimo passo nell'imbuto di vendita. Quando i visitatori arrivano su questa pagina, dovrebbero aver completato l'intero processo dell'imbuto di vendita. Se questa pagina viene indicizzata, significa che si potrebbero perdere potenziali clienti, o che si potrebbero ricevere contatti non validi.
Il comando per bloccare una tale pagina è:
Disallow:/thank-you/
Noindex e NoFollow
Come abbiamo detto in tutto questo articolo, l'utilizzo di robots.txt non è una garanzia al 100% che la tua pagina non verrà indicizzata. Vediamo due modi per assicurarsi che la tua pagina bloccata non venga effettivamente indicizzata.
La direttiva noindex
Questo funziona in congiunzione con il comando disallow. Utilizza entrambi nella tua direttiva, come in:
Disallow:/thank-you/
La direttiva nofollow
Questo funziona per istruire specificamente i bot di Google a non esplorare i link su una pagina. Questo non fa parte del file robots.txt. Per utilizzare il comando nofollow per bloccare le pagine dall'essere esplorate e indicizzate, è necessario trovare il codice sorgente della pagina specifica che non si desidera venga indicizzata.
Incolla questo tra il tag di apertura e di chiusura head:
<meta name = "robots" content="nofollow">
Puoi utilizzare contemporaneamente sia “nofollow” che “noindex”. Usa questa linea di codice:
<meta name = "robots" content="noindex,nofollow">
Generazione di robots.txt
Se trovi difficile scrivere robots.txt utilizzando tutti i formati e la sintassi necessari che devi comprendere e seguire, puoi utilizzare strumenti che semplificano il processo. Un buon esempio è il nostro generatore gratuito di robots.txt.
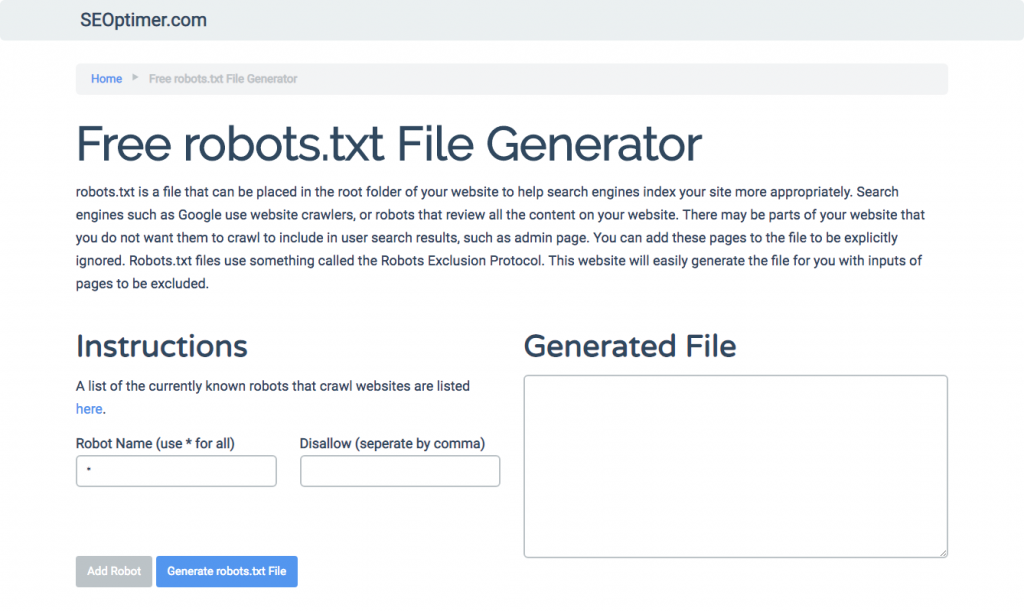
Questo strumento ti permette di scegliere il tipo di risultato che hai bisogno sul tuo sito web e il file o le directory che vuoi aggiungere. Puoi anche testare il tuo file e vedere come sta andando la tua concorrenza.
Testare il tuo file robots.txt
Devi testare il tuo file robots.txt per assicurarti che funzioni come previsto.
Usa il tester di robots.txt di Google.
Per fare ciò, accedi al tuo account di Webmaster.
- Successivamente, seleziona la tua proprietà. In questo caso, è il tuo sito web.
- Fai clic su "crawl" nella barra laterale sinistra.
- Fai clic su "robots.txt tester".
- Sostituisci qualsiasi codice esistente con il tuo nuovo file robots.txt.
- Fai clic su "test".
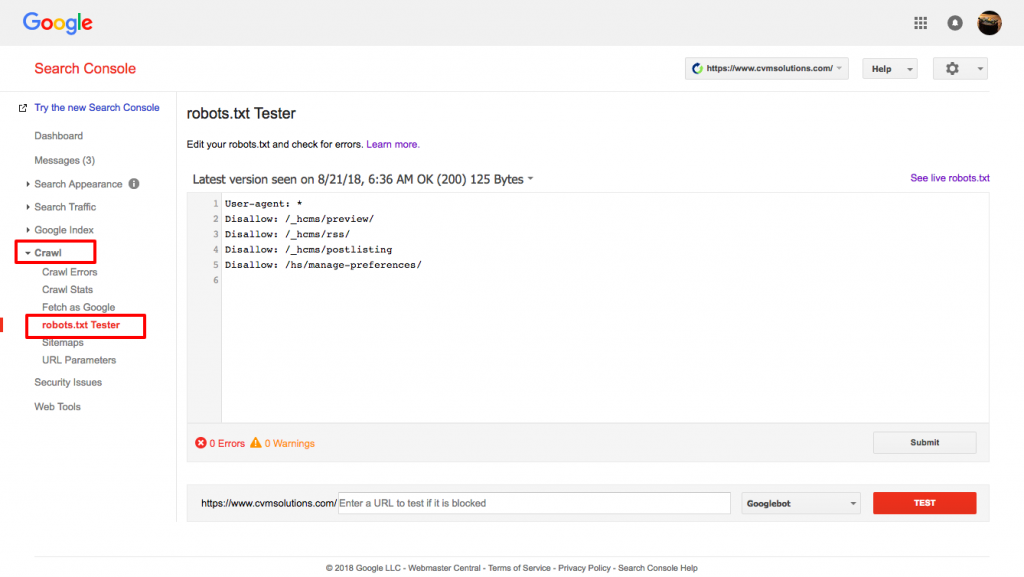
Dovresti essere in grado di vedere una casella di testo "consentito" se il file è valido. Per maggiori informazioni, consulta questa guida dettagliata su Google robots.txt tester.
Se il tuo file è valido, è ora il momento di caricarlo nella tua directory principale o salvarlo lì se come un altro file robots.txt.
Come aggiungere robots.txt al tuo sito WordPress
Per aggiungere un file robots.txt al tuo file WordPress, copriremo le opzioni dei plugin e FTP.
Per l'opzione del plugin, puoi utilizzare un plug-in come All in One SEO Pack
Per fare ciò, accedi al tuo cruscotto di WordPress
Scorri verso il basso fino a quando non arrivi a "plugins"
Fai clic su "aggiungi nuovo"
Vai a "cerca plugin"
Scrivi “All in One SEO Pack”
Installa e attiva
Nella sezione Impostazioni Generali del plugin All in One SEO, puoi configurare le regole noindex e nofollow da includere nel tuo file robots.txt.
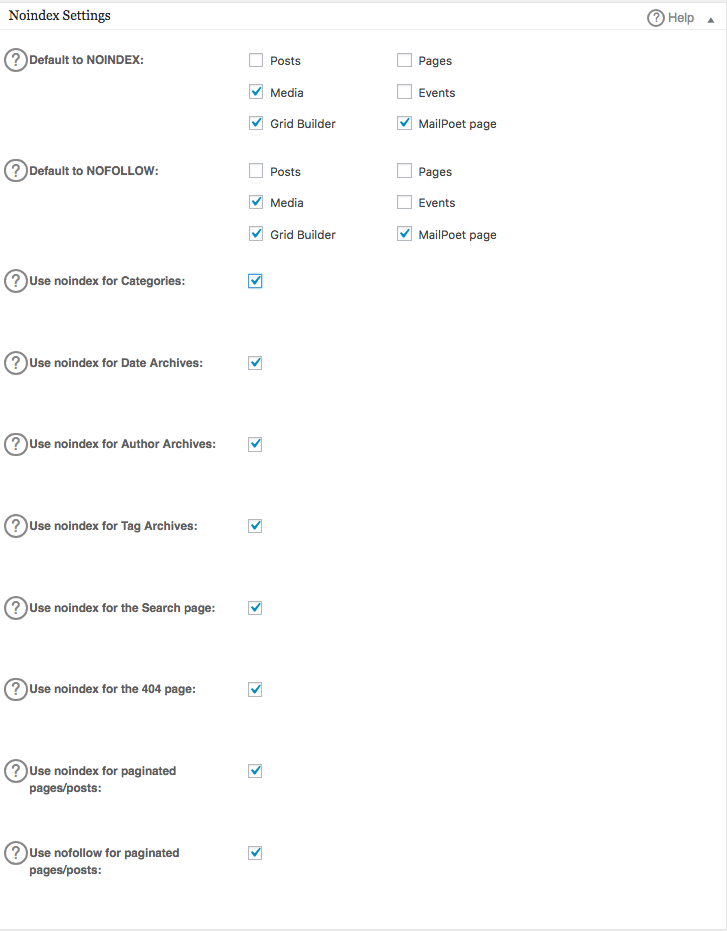
Puoi specificare quali URL dovrebbero essere NOINDEX, NOFOLLOW. Lasciando queste opzioni non selezionate, l'impostazione predefinita sarà quella di essere indicizzati:
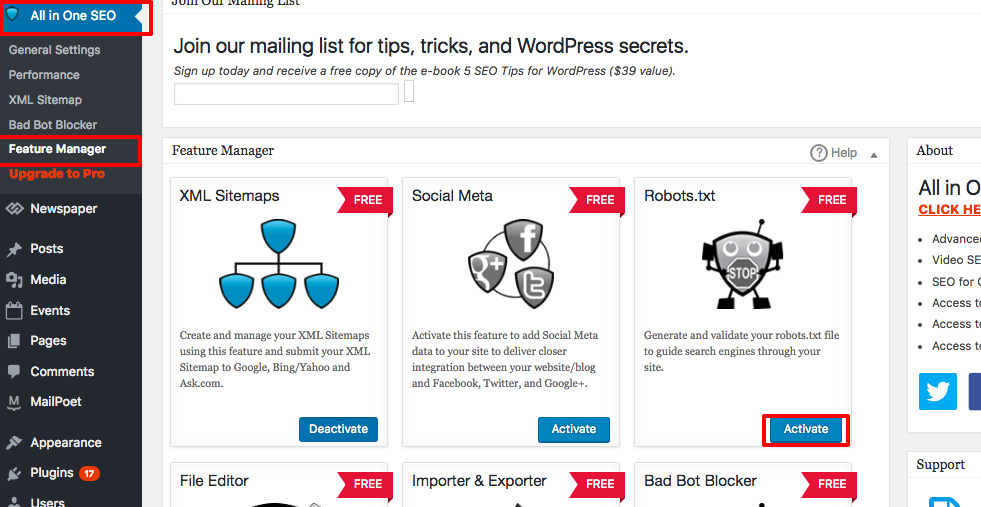
Per creare regole avanzate nel tuo file robots.txt, clicca sul gestore delle funzionalità, poi sul pulsante attiva proprio sotto robots.txt.
Robots.txt ora appare appena sotto il gestore delle funzionalità. Cliccaci sopra. Vedrai una sezione chiamata "crea un file robots.txt".
C'è una sezione del costruttore di regole che ti permette di scegliere e compilare le regole che desideri per il tuo sito, a seconda di ciò che vuoi o non vuoi che venga indicizzato.
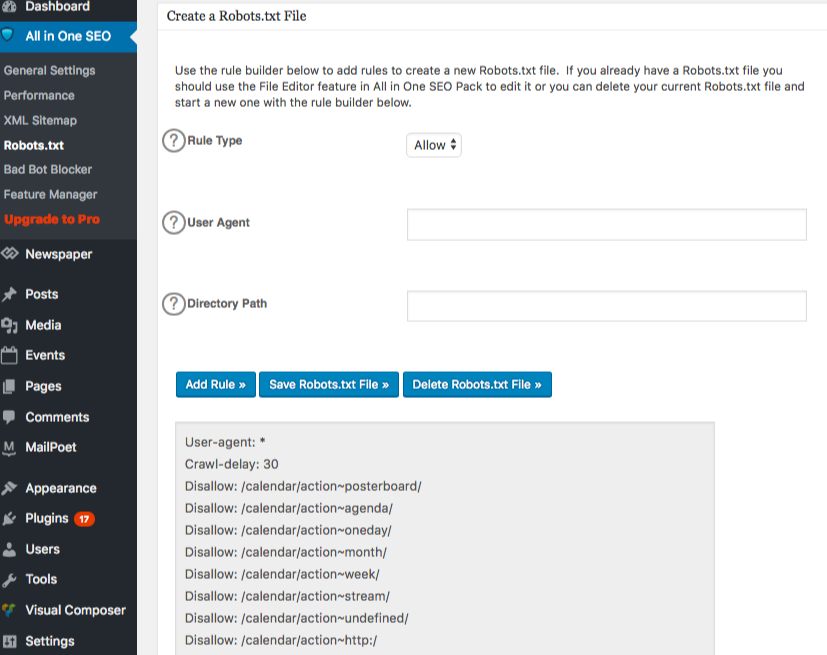
Una volta che hai finito di creare la regola, clicca su "aggiungi regola".
La regola sarà quindi elencata nella cartella robots.txt creata.
Vedrai un messaggio per indicare che le “All in One Options” sono state aggiornate.
Un altro metodo che puoi utilizzare è caricare il tuo file robots.txt direttamente sul tuo client FTP (File Transfer Protocol) come FileZilla.
Una volta che hai generato il tuo file robots.txt, puoi localizzarlo e sostituirlo. Il tuo file robots.txt si troverà in: "/applications/[NOME DELLA CARTELLA]/public_html".
Come modificare il file robots.txt sul tuo Wix
Wix genera un file robots.txt per i siti web che utilizzano la piattaforma di creazione web. Per visualizzarlo, aggiungi "/robots.txt" al tuo dominio. I file aggiunti a robots.txt hanno a che fare con la struttura dei siti Wix, per esempio, i link noflashhtml, che non contribuiscono al valore SEO del tuo sito alimentato da Wix.
Non puoi modificare il tuo file robots.txt se il tuo sito è gestito da Wix. Puoi solo utilizzare altre opzioni come aggiungere un "tag noindex" alle pagine che non vuoi vengano indicizzate.
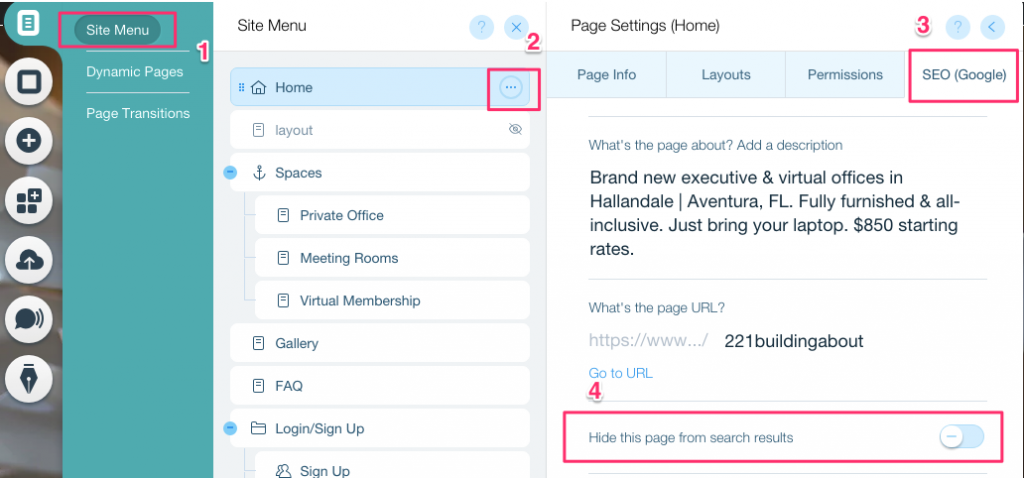
Per creare un tag noindex per una pagina specifica:
- Fai clic su Menu del sito
- Fai clic sull'opzione Impostazioni per quella specifica pagina
- Seleziona SEO (Google) tag
- Attiva Nascondi questa pagina dai risultati di ricerca
Come modificare il file robots.txt sul tuo Shopify
Proprio come con Wix, Shopify aggiunge automaticamente un file robots.txt non modificabile al tuo sito. Se non vuoi che alcune pagine vengano indicizzate, devi aggiungere il "tag noindex" o ritirare la pubblicazione della pagina. Puoi anche aggiungere meta tag nella sezione header delle pagine che non vuoi vengano indicizzate. Questo è ciò che dovresti aggiungere al tuo header:
<meta name= "robots" content = "noindex">
Shopify ha creato una guida dettagliata su come nascondere le pagine dai motori di ricerca che puoi seguire.
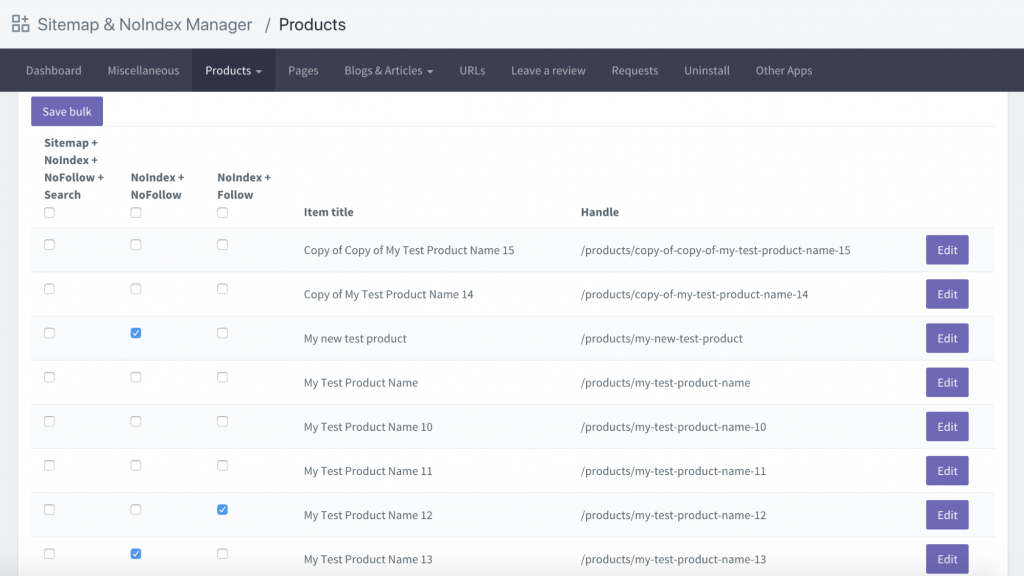
Un'altra opzione è scaricare un'app chiamata Sitemap & NoIndex Manager di Orbis Labs. Puoi semplicemente selezionare le opzioni noindex o nofollow per ciascuna pagina sul tuo sito Shopify: