
Jika Anda menerima peringatan ‘Terindeks, meskipun diblokir oleh robots.txt’ di Google Search Console, Anda akan ingin memperbaikinya secepat mungkin, karena hal itu bisa mempengaruhi kemampuan halaman Anda untuk mendapatkan peringkat sama sekali di Halaman Hasil Mesin Pencari (SERPS).
Sebuah file robots.txt adalah file yang berada dalam direktori situs web Anda, yang memberikan beberapa instruksi untuk Search Engine Crawlers, seperti bot Google, tentang file mana yang harus dan tidak boleh dilihat.
‘Diindeks, meskipun diblokir oleh robots.txt’ menunjukkan bahwa Google telah menemukan halaman Anda, tetapi juga telah menemukan instruksi untuk mengabaikannya di file robots Anda (yang berarti halaman tersebut tidak akan muncul dalam hasil pencarian).
Terkadang ini disengaja, atau kadang-kadang ini tidak disengaja, karena beberapa alasan yang diuraikan di bawah ini, dan dapat diperbaiki.
Ini adalah tangkapan layar dari notifikasi:
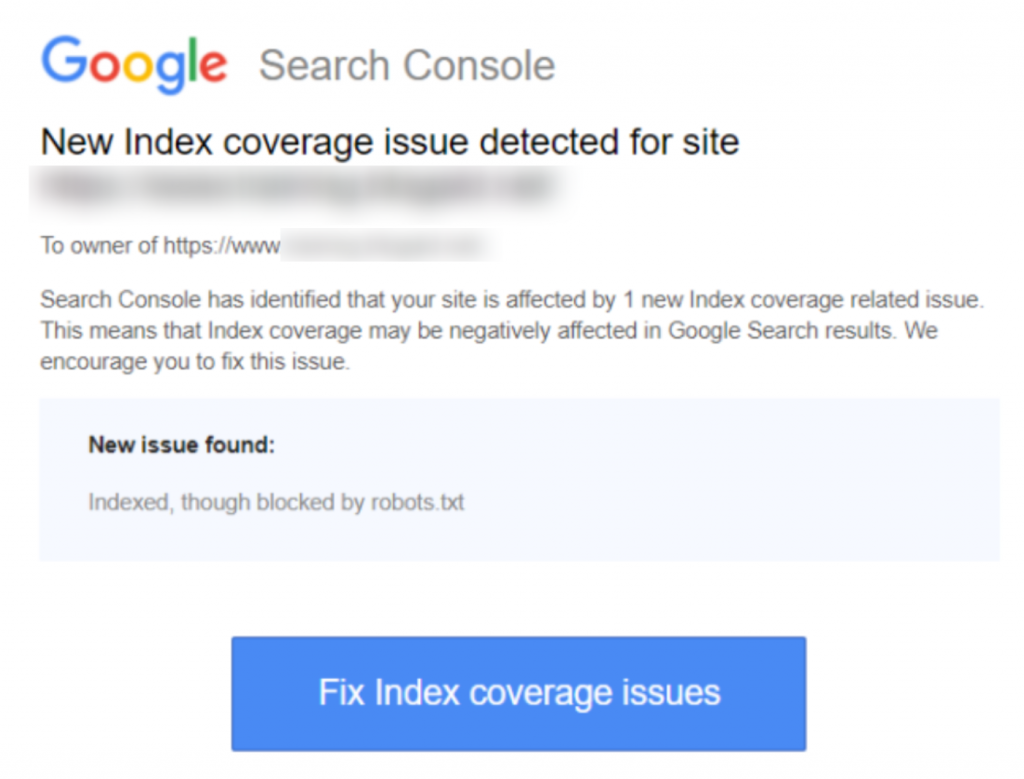
Identifikasi halaman atau URL yang terpengaruh
Jika Anda menerima notifikasi dari Google Search Console (GSC), Anda perlu mengidentifikasi halaman atau URL tertentu yang dimaksud.
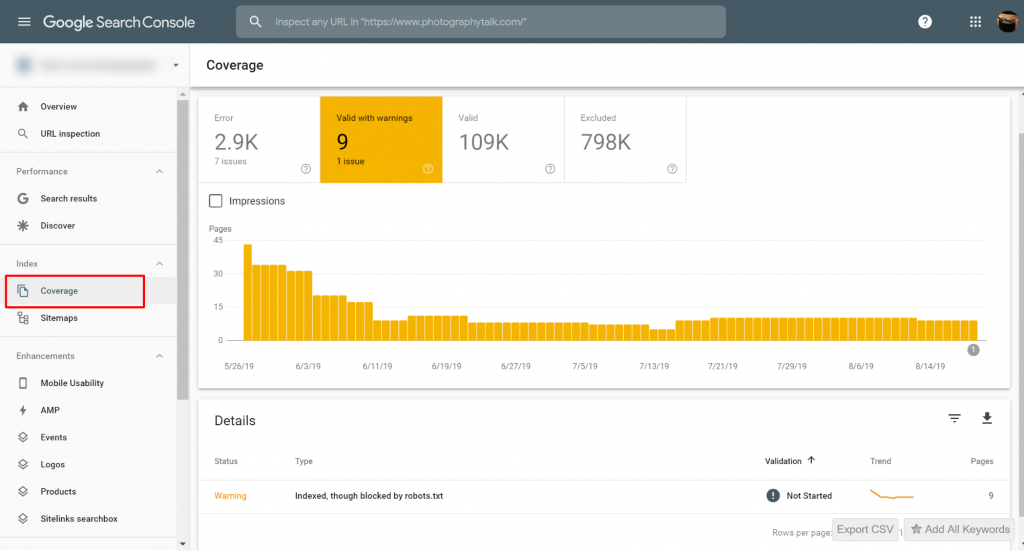
Anda dapat melihat halaman dengan masalah Indexed, though blocked by robots.txt di Google Search Console>>Coverage. Jika Anda tidak melihat label peringatan, maka Anda bebas dan tidak ada masalah.
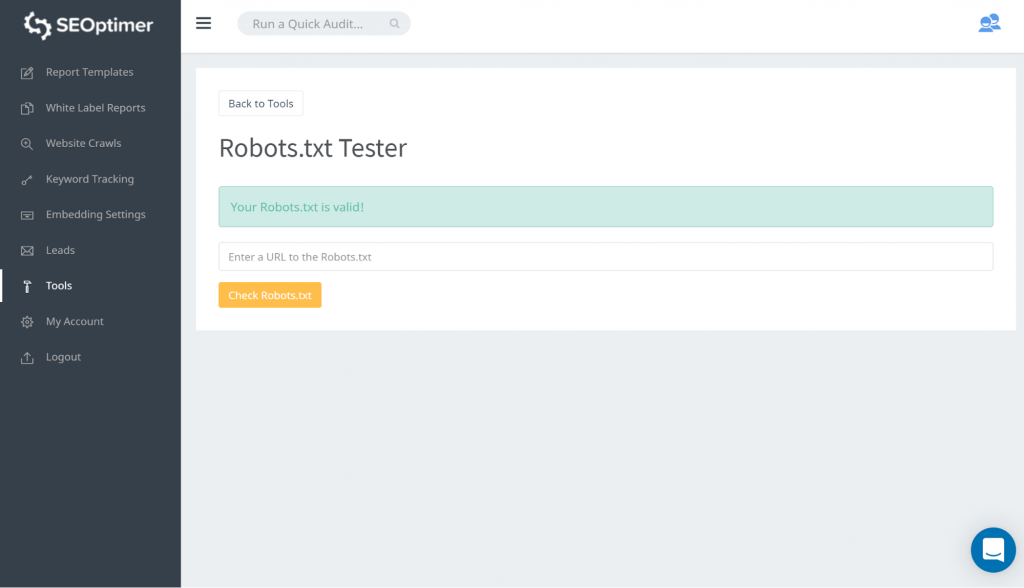
Cara untuk menguji robots.txt Anda adalah dengan menggunakan robots.txt tester kami. Anda mungkin menemukan bahwa Anda tidak keberatan dengan apa pun yang diblokir tetap 'diblokir'. Oleh karena itu, Anda tidak perlu mengambil tindakan apa pun.
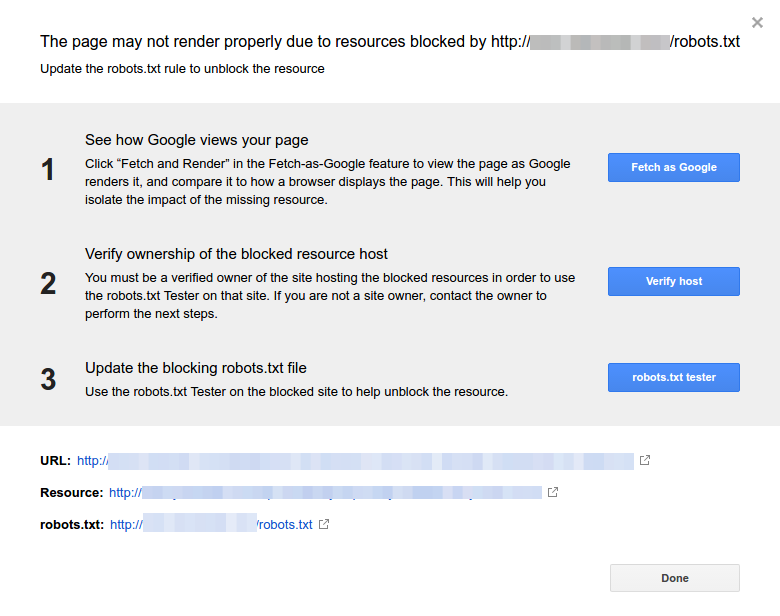
Anda juga dapat mengikuti tautan GSC ini. Kemudian Anda perlu:
- Buka daftar sumber daya yang diblokir dan pilih domainnya.
- Klik setiap sumber daya. Anda seharusnya melihat popup ini:
Identifikasi alasan untuk notifikasi
Pemberitahuan dapat berasal dari beberapa alasan. Berikut adalah alasan-alasan umum:
Tetapi pertama-tama, bukan masalah jika ada halaman yang diblokir oleh robots.txt., Hal tersebut mungkin telah dirancang karena alasan, seperti, pengembang ingin memblokir halaman / kategori yang tidak perlu atau duplikat. Jadi, apa saja ketidaksesuaian tersebut?
Format URL Salah
Terkadang, masalah mungkin timbul dari URL yang sebenarnya bukan sebuah halaman. Sebagai contoh, jika URL https://www.seoptimer.com/?s=digital+marketing, Anda perlu tahu halaman mana yang diarahkan oleh URL tersebut.
Jika itu adalah halaman yang berisi konten penting yang benar-benar Anda ingin pengguna Anda lihat, maka Anda perlu mengubah URL. Ini mungkin dilakukan pada Sistem Manajemen Konten (CMS) seperti Wordpress di mana Anda dapat mengedit slug halaman.
Jika halaman tidak penting, atau dengan contoh /?s=digital+marketing kita, itu adalah kueri pencarian dari blog kita maka tidak perlu memperbaiki kesalahan GSC.
Itu tidak membuat perbedaan apakah itu diindeks atau tidak, karena itu bukan URL yang sebenarnya, tetapi sebuah kueri pencarian. Sebagai alternatif, Anda dapat menghapus halaman tersebut.
Halaman yang harus diindeks
Ada beberapa alasan mengapa halaman yang seharusnya diindeks tidak terindeks. Berikut adalah beberapa di antaranya:
- Apakah Anda sudah memeriksa direktif robot Anda? Anda mungkin telah menyertakan direktif dalam file robots.txt Anda yang melarang pengindeksan halaman yang sebenarnya harus diindeks, misalnya, tag dan kategori. Tag dan kategori adalah URL yang sebenarnya di situs Anda.
- Apakah Anda mengarahkan Googlebot ke rantai pengalihan? Googlebot akan melewati setiap tautan yang dapat mereka temukan dan melakukan yang terbaik untuk membaca demi pengindeksan. Namun, jika Anda mengatur beberapa pengalihan yang panjang dan dalam, atau jika halaman tersebut tidak dapat dijangkau, Googlebot akan berhenti mencari.
- Apakah tautan kanonikal telah diimplementasikan dengan benar? Tag kanonikal digunakan dalam header HTML untuk memberi tahu Googlebot mana halaman yang diutamakan dan kanonikal dalam kasus konten yang duplikat. Setiap halaman seharusnya memiliki tag kanonikal. Sebagai contoh, Anda memiliki halaman yang diterjemahkan ke dalam bahasa Spanyol. Anda akan menautkan kanonikal URL bahasa Spanyol tersebut dan Anda ingin kanonikal halaman tersebut kembali ke versi bahasa Inggris default Anda.
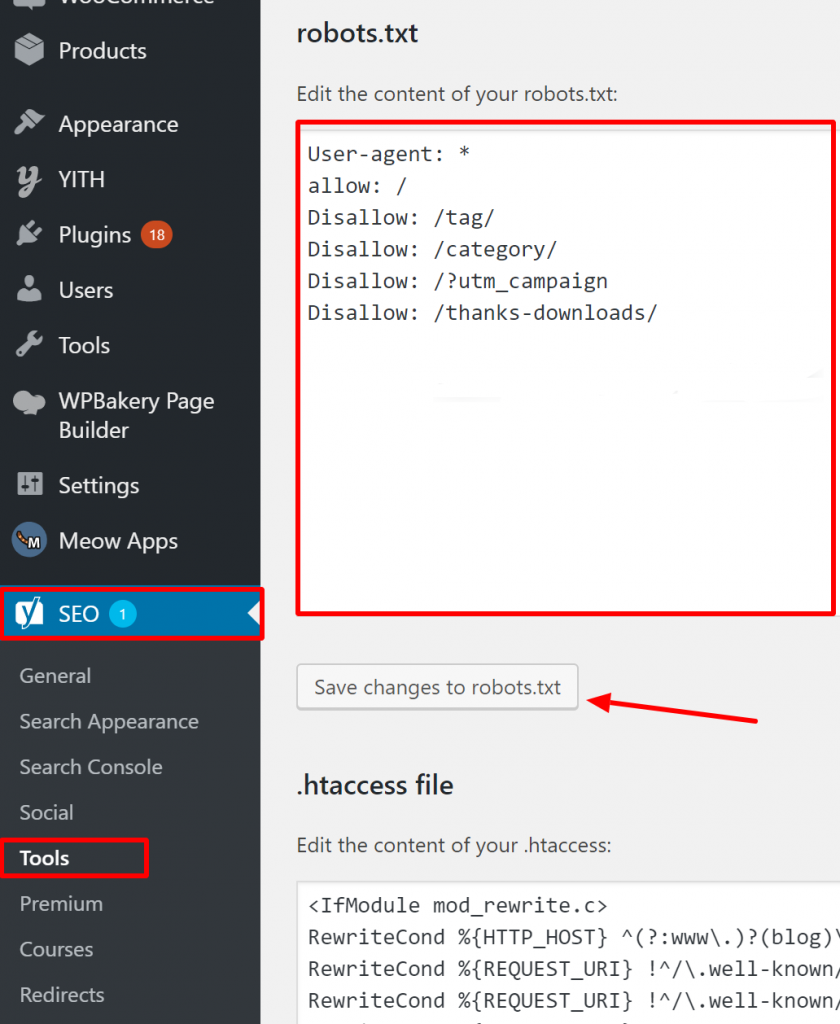
Bagaimana memverifikasi Robots.txt Anda sudah benar di WordPress?
Untuk WordPress, jika file robots.txt Anda merupakan bagian dari instalasi situs, gunakan Plugin Yoast untuk mengeditnya. Jika file robots.txt yang menyebabkan masalah berada di situs lain yang bukan milik Anda, Anda perlu berkomunikasi dengan pemilik situs tersebut dan meminta mereka untuk mengedit file robots.txt mereka.
Halaman yang tidak seharusnya diindeks
Ada beberapa alasan mengapa halaman yang seharusnya tidak diindeks menjadi terindeks. Berikut adalah beberapa di antaranya:
Direktif Robots.txt yang 'mengatakan' bahwa sebuah halaman tidak boleh diindeks. Perhatikan bahwa Anda perlu mengizinkan halaman dengan direktif 'noindex' untuk di-crawl sehingga bot mesin pencari 'tahu' bahwa halaman tersebut tidak boleh diindeks.
Di file robots.txt Anda, pastikan bahwa:
- Baris 'disallow' tidak langsung mengikuti baris 'user-agent'.
- Tidak ada lebih dari satu blok 'user-agent'.
- Karakter Unicode tak terlihat - Anda perlu menjalankan file robots.txt Anda melalui editor teks yang akan mengonversi encoding. Ini akan menghapus karakter khusus apa pun.
Halaman dihubungkan dari situs lain. Halaman dapat diindeks jika dihubungkan dari situs lain, meskipun dilarang dalam robots.txt. Namun dalam kasus ini, hanya URL dan teks jangkar yang muncul dalam hasil pencarian mesin pencari. Inilah cara URL tersebut ditampilkan di halaman hasil pencarian mesin pencari (SERP):
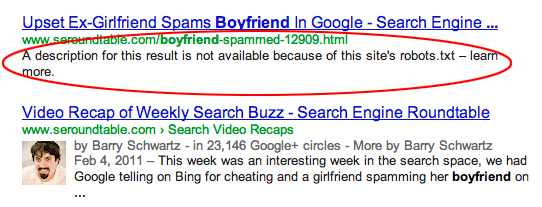 sumber gambar Webmasters StackExchange
sumber gambar Webmasters StackExchange
Salah satu cara untuk mengatasi masalah pemblokiran robots.txt adalah dengan melindungi file tersebut dengan kata sandi di server Anda.
Sebagai alternatif, hapus halaman dari robots.txt atau gunakan meta tag berikut untuk memblokir
mereka:
<meta name="robots" content="noindex">
URL Lama
Jika Anda telah membuat konten baru atau situs baru dan menggunakan direktif ‘noindex’ di robots.txt untuk memastikan bahwa konten tersebut tidak terindeks, atau baru-baru ini mendaftar untuk GSC, ada dua opsi untuk memperbaiki masalah yang diblokir oleh robots.txt:
- Beri waktu kepada Google untuk akhirnya menghapus URL lama dari indeksnya
- 301 redirect URL lama ke URL yang sekarang
Pada kasus pertama, Google pada akhirnya akan menghapus URL dari indeksnya jika yang mereka lakukan hanyalah mengembalikan 404 (yang berarti bahwa halaman tersebut tidak ada). Tidak disarankan untuk menggunakan plugin untuk mengarahkan ulang 404 Anda. Plugin tersebut bisa menyebabkan masalah yang mungkin mengakibatkan GSC mengirimkan peringatan 'diblokir oleh robots.txt' kepada Anda.
File robots.txt Virtual
Ada kemungkinan mendapatkan notifikasi meskipun Anda tidak memiliki file robots.txt. Ini karena situs berbasis CMS (Customer Management Systems), contohnya WordPress memiliki file robots.txt virtual. Plug-in juga mungkin mengandung file robots.txt. Ini bisa jadi yang menyebabkan masalah di situs Anda.
Robots.txt virtual ini perlu ditimpa oleh file robots.txt milik Anda sendiri. Pastikan bahwa robots.txt Anda mencakup direktif untuk mengizinkan semua bot mesin pencari merayapi situs Anda. Ini adalah satu-satunya cara agar mereka dapat memberitahu URL mana yang harus diindeks atau tidak.
Ini adalah direktif yang memungkinkan semua bot untuk merayapi situs Anda:
User-agent: *
Disallow: /
Ini berarti 'tidak melarang apa pun'.
Kesimpulan
Kami telah melihat peringatan ‘Indexed, though blocked by robots.txt’, apa artinya, bagaimana cara mengidentifikasi halaman atau URL yang terpengaruh, serta alasan di balik peringatan tersebut. Kami juga telah melihat bagaimana cara memperbaikinya. Perhatikan bahwa peringatan tersebut tidak sama dengan kesalahan di situs Anda. Namun, jika tidak diperbaiki, hal tersebut dapat mengakibatkan halaman paling penting Anda tidak terindeks yang tidak baik untuk pengalaman pengguna.










