Apa itu Robots.txt?
Robots.txt adalah file dalam bentuk teks yang memberi instruksi kepada bot crawler untuk mengindeks atau tidak mengindeks halaman tertentu. Ini juga dikenal sebagai penjaga gerbang untuk seluruh situs Anda. Tujuan pertama bot crawler adalah untuk menemukan dan membaca file robots.txt, sebelum mengakses sitemap Anda atau halaman atau folder apa pun.
Dengan robots.txt, Anda dapat lebih spesifik:
- Atur bagaimana bot mesin pencari merayapi situs Anda
- Menyediakan akses tertentu
- Membantu spider mesin pencari mengindeks konten halaman
- Menunjukkan cara menyajikan konten kepada pengguna
Robots.txt adalah bagian dari Robots Exclusion Protocol (R.E.P), yang terdiri dari direktif tingkat situs/halaman/URL. Meskipun bot mesin pencari masih dapat merayapi seluruh situs Anda, terserah Anda untuk membantu mereka memutuskan apakah halaman tertentu layak untuk waktu dan usaha.
Mengapa Anda Memerlukan Robots.txt
Situs Anda tidak memerlukan file robots.txt agar dapat berfungsi dengan baik. Alasan utama Anda memerlukan file robots.txt adalah agar ketika bot merayapi halaman Anda, mereka meminta izin untuk merayap sehingga mereka dapat mencoba mengambil informasi tentang halaman untuk diindeks. Selain itu, situs web tanpa file robots.txt pada dasarnya meminta bot crawler untuk mengindeks situs sesuai keinginan mereka. Penting untuk dipahami bahwa bot akan tetap merayapi situs Anda tanpa file robots.txt.
Lokasi dari file robots.txt Anda juga penting karena semua bot akan mencari www.123.com/robots.txt. Jika mereka tidak menemukan apa pun di sana, mereka akan mengasumsikan bahwa situs tersebut tidak memiliki file robots.txt dan mengindeks semuanya. File tersebut harus berupa file teks ASCII atau UTF-8. Juga penting untuk dicatat bahwa aturan-aturan bersifat sensitif terhadap huruf besar-kecil.
Berikut adalah beberapa hal yang akan dan tidak akan dilakukan oleh robots.txt:
- Berkas ini mampu mengontrol akses crawler ke area tertentu di situs web Anda. Anda perlu sangat hati-hati saat mengatur robots.txt karena mungkin untuk memblokir seluruh situs web agar tidak terindeks.
- Ini mencegah konten duplikat dari terindeks dan muncul dalam hasil pencarian mesin pencari.
- Berkas ini menentukan jeda crawl untuk mencegah server kelebihan beban ketika crawler sedang memuat banyak konten secara bersamaan.
Berikut adalah beberapa Googlebot yang mungkin merayapi situs Anda dari waktu ke waktu:
| Web Crawler | String Agen-Pengguna |
| Berita Googlebot | Googlebot-News |
| Googlebot Images | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobile (ponsel fitur) | SAMSUNG-SGH-E250/1.0 Profil/MIDP-2.0 Konfigurasi/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (kompatibel; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Smartphone Google | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (kompatibel; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (kompatibel; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (kualitas halaman arahan PPC) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app crawler (mengambil sumber daya untuk seluler) | AdsBot-Google-Mobile-Apps |
Anda dapat menemukan daftar bot tambahan di sini.
- Berkas-berkas tersebut membantu dalam menentukan lokasi dari peta situs.
- Ini juga mencegah bot mesin pencari dari mengindeks berbagai berkas di situs web seperti gambar dan PDF.
Ketika bot ingin mengunjungi situs web Anda (misalnya, www.123.com), ia awalnya memeriksa www.123.com/robots.txt dan menemukan:
User-agent: *
Disallow: /
Contoh ini menginstruksikan semua (User-agents*) bot mesin pencari untuk tidak mengindeks (Disallow: /) situs web.
Jika Anda menghapus garis miring ke depan dari Disallow, seperti pada contoh di bawah ini,
User-agent: *
Disallow:
bot akan dapat merayapi dan mengindeks semua hal di situs web. Inilah mengapa penting untuk memahami sintaks dari robots.txt.
Memahami sintaks robots.txt
Sintaks robots.txt dapat dipikirkan sebagai "bahasa" dari file robots.txt. Ada 5 istilah umum yang kemungkinan akan Anda temui dalam file robots.txt. Mereka adalah:
- User-agent: Web crawler spesifik yang Anda berikan instruksi crawl (biasanya mesin pencari). Daftar sebagian besar user agent dapat ditemukan di sini.
- Disallow: Perintah yang digunakan untuk memberitahu agen pengguna agar tidak merayapi URL tertentu. Hanya satu baris "Disallow:" yang diizinkan untuk setiap URL.
- Allow (Hanya berlaku untuk Googlebot): Perintah ini memberitahu Googlebot bahwa ia dapat mengakses halaman atau subfolder meskipun halaman induk atau subfolder tersebut mungkin tidak diizinkan.
- Crawl-delay: Jumlah milidetik yang harus ditunggu oleh crawler sebelum memuat dan merayapi konten halaman. Perhatikan bahwa Googlebot tidak mengakui perintah ini, tetapi laju merayap dapat diatur di Google Search Console.
- Peta Situs: Digunakan untuk menunjukkan lokasi dari setiap peta situs XML yang terkait dengan sebuah URL. Perhatikan bahwa perintah ini hanya didukung oleh Google, Ask, Bing, dan Yahoo.
Hasil instruksi Robots.txt
Anda mengharapkan tiga hasil ketika Anda mengeluarkan instruksi robots.txt:
- Izin penuh
- Larangan penuh
- Izin bersyarat
Mari kita selidiki masing-masing di bawah ini.
Izin Penuh
Hasil ini berarti seluruh konten di situs web Anda dapat di-crawl. File robots.txt dimaksudkan untuk memblokir crawling oleh bot mesin pencari, sehingga perintah ini bisa sangat penting.
Hasil ini bisa berarti bahwa Anda tidak memiliki berkas robots.txt di situs web Anda sama sekali. Meskipun Anda tidak memilikinya, bot mesin pencari akan tetap mencarinya di situs Anda. Jika mereka tidak mendapatkannya, maka mereka akan merayapi semua bagian dari situs web Anda.
Opsi lain di bawah hasil ini adalah untuk membuat file robots.txt tetapi biarkan kosong. Ketika spider datang untuk merayapi, ia akan mengidentifikasi dan bahkan membaca file robots.txt. Karena tidak akan menemukan apa pun di sana, ia akan melanjutkan untuk merayapi sisa situs.
Jika Anda memiliki file robots.txt dan memiliki dua baris berikut ini di dalamnya,
User-agent:*
Disallow:
mesin pencari spider akan merayapi situs web Anda, mengidentifikasi file robots.txt dan membacanya. Ia akan sampai pada baris kedua dan kemudian melanjutkan untuk merayapi sisa situs.
Larangan Penuh
Di sini, tidak ada konten yang akan di-crawl dan di-indeks. Perintah ini dikeluarkan oleh baris ini:
User-agent:*
Disallow:/
Ketika kita berbicara tentang tidak ada konten, kami maksudkan bahwa tidak ada yang dari situs web (konten, halaman, dll.) yang dapat di-crawl. Ini tidak pernah menjadi ide yang baik.
Izin Bersyarat
Ini berarti hanya konten tertentu di situs web yang dapat di-crawl.
Sebuah izin bersyarat memiliki format sebagai berikut:
User-agent:*
Disallow:/
User-agent: Mediapartner-Google
Allow:/
Anda dapat menemukan sintaks lengkap robots.txt di sini.
Perhatikan bahwa halaman yang diblokir masih dapat diindeks meskipun Anda telah melarang URL seperti yang ditunjukkan pada gambar di bawah ini:
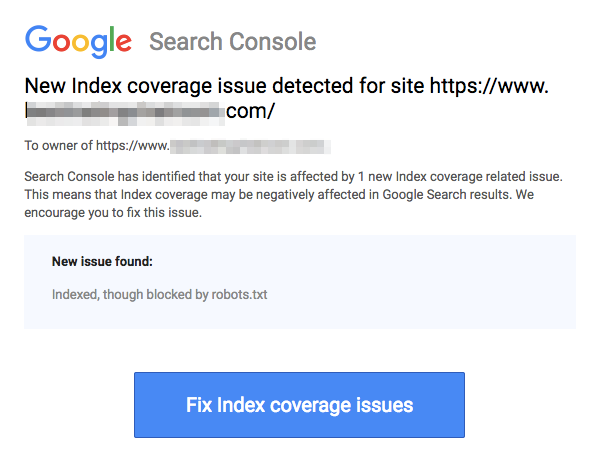
Anda mungkin menerima email dari mesin pencari bahwa URL Anda telah diindeks seperti pada tangkapan layar di atas. Jika URL yang Anda larang terhubung dari situs lain, seperti teks jangkar dalam tautan, itu akan diindeks. Solusi untuk ini adalah 1) melindungi file Anda dengan kata sandi di server Anda, 2) menggunakan tag meta noindex, atau 3) menghapus halaman sepenuhnya.
Bisakah robot tetap memindai dan mengabaikan file robots.txt saya?
Ya. memang mungkin bahwa robot dapat mengabaikan robots.txt. Ini karena Google menggunakan faktor lain seperti informasi eksternal dan tautan masuk untuk menentukan apakah halaman harus diindeks atau tidak. Jika Anda tidak ingin halaman diindeks sama sekali, Anda harus menggunakan tag meta robots noindex. Pilihan lainnya adalah menggunakan header HTTP X-Robots-Tag.
Bisakah Saya Memblokir Hanya Robot yang Buruk?
Secara teori, mungkin untuk memblokir robot jahat, tetapi mungkin sulit untuk melakukannya dalam praktik. Mari kita lihat beberapa cara untuk melakukannya:
- Anda dapat memblokir robot yang buruk dengan mengecualikannya. Namun, Anda perlu mengetahui nama robot tertentu yang memindai di bidang User-Agent. Kemudian Anda perlu menambahkan sebuah bagian dalam file robots.txt Anda yang mengecualikan robot yang buruk tersebut.
- Konfigurasi server. Ini hanya akan berfungsi jika operasi robot jahat berasal dari satu alamat IP. Konfigurasi server atau firewall jaringan akan memblokir robot jahat dari mengakses server web Anda.
- Menggunakan konfigurasi aturan firewall canggih. Ini akan secara otomatis memblokir akses ke berbagai alamat IP di mana salinan robot jahat tersebut ada. Contoh baik dari bot yang beroperasi di berbagai alamat IP adalah dalam kasus PC yang diretas yang bahkan bisa menjadi bagian dari Botnet yang lebih besar (pelajari lebih lanjut tentang Botnet di sini).
Jika robot jahat beroperasi dari satu alamat IP, Anda dapat memblokir aksesnya ke server web Anda melalui konfigurasi server atau dengan firewall jaringan.
Jika salinan robot beroperasi di sejumlah alamat IP yang berbeda, maka akan menjadi lebih sulit untuk memblokirnya. Opsi terbaik dalam kasus ini adalah menggunakan konfigurasi aturan firewall canggih yang secara otomatis memblokir akses ke alamat IP yang membuat banyak koneksi; sayangnya, ini juga dapat mempengaruhi akses bot yang baik juga.
Apa saja praktik terbaik SEO saat menggunakan robots.txt?
Pada titik ini, Anda mungkin bertanya-tanya bagaimana cara menavigasi perairan robots.txt yang sangat rumit ini. Mari kita lihat ini lebih detail:
- Pastikan Anda tidak memblokir konten atau bagian situs Anda yang ingin Anda lakukan crawling.
- Gunakan mekanisme pemblokiran yang berbeda dari robots.txt jika Anda ingin link equity dapat diteruskan dari halaman dengan robots.txt (yang berarti halaman tersebut praktis diblokir) ke tujuan tautan.
- Jangan gunakan robots.txt untuk mencegah data sensitif seperti informasi pengguna pribadi muncul dalam hasil pencarian mesin pencari. Hal ini dapat memungkinkan halaman lain untuk menautkan ke halaman yang mengandung informasi pengguna pribadi yang mungkin menyebabkan halaman tersebut diindeks. Dalam kasus ini, robots.txt telah diabaikan. Opsi lain yang dapat Anda jelajahi di sini adalah perlindungan kata sandi atau direktif meta noindex.
- Tidak perlu menentukan direktif untuk setiap crawler mesin pencari karena sebagian besar user agent, jika termasuk dalam mesin pencari yang sama, mengikuti aturan yang sama. Google menggunakan Googlebot untuk mesin pencari dan Googlebot Image untuk pencarian gambar. Satu-satunya keuntungan dari mengetahui cara menentukan setiap crawler adalah Anda dapat menyetel dengan tepat bagaimana konten di situs Anda di-crawl.
- Jika Anda telah mengubah file robots.txt dan Anda ingin Google memperbaruinya lebih cepat, kirimkan langsung ke Google. Untuk instruksi tentang cara melakukan itu, klik di sini. Penting untuk dicatat bahwa mesin pencari menyimpan konten robots.txt dan memperbarui konten yang disimpan setidaknya sekali sehari.
Panduan dasar robots.txt
Sekarang setelah Anda memiliki pemahaman dasar tentang SEO yang berkaitan dengan robots.txt, apa saja yang harus Anda perhatikan ketika menggunakan robots.txt? Dalam bagian ini, kita akan melihat beberapa pedoman yang harus diikuti ketika menggunakan robots.txt, meskipun penting untuk benar-benar membaca seluruh sintaks.
Format dan lokasi
Editor teks yang Anda pilih untuk digunakan dalam membuat file robots.txt harus dapat membuat file teks ASCII standar atau UTF-8. Menggunakan pengolah kata bukanlah ide yang baik karena beberapa karakter yang mungkin mempengaruhi crawling mungkin ditambahkan.
Walaupun hampir semua editor teks dapat digunakan untuk membuat file robots.txt Anda, alat ini sangat disarankan karena memungkinkan untuk melakukan pengujian terhadap situs Anda.
Berikut adalah lebih banyak panduan tentang format dan lokasi:
- Anda harus menamai file yang Anda buat “robots.txt” karena file tersebut sensitif terhadap huruf besar dan kecil. Tidak ada karakter huruf besar yang digunakan.
- Anda hanya dapat memiliki satu file robots.txt di seluruh situs.
- Berkas robots.txt hanya terletak di satu tempat: akar dari host situs web yang berlaku. Perhatikan bahwa itu tidak dapat ditempatkan dalam subdirektori. Jika situs web Anda adalahhttp://www.123.com/, maka lokasi dari robots.txt adalah http://www.123.com/robots.txt, tidak http://www.123.com/pages/robots.txtPerhatikan bahwa file robots.txt dapat berlaku untuk subdomain (http://website.123.com/robots.txt) dan bahkan port non-standar, sepertihttp://www.123.com: 8181/robots.txtMohon berikan teks yang ingin Anda terjemahkan ke dalam Bahasa Indonesia.
Seperti yang telah disebutkan sebelumnya, robots.txt bukanlah cara terbaik untuk mencegah informasi pribadi yang sensitif dari diindeks. Ini adalah kekhawatiran yang valid, terutama sekarang dengan diterapkannya GDPR baru-baru ini. Privasi data tidak boleh dikompromikan. Titik.
Bagaimana Anda kemudian memastikan bahwa robots.txt tidak menampilkan data sensitif dalam hasil pencarian?
Menggunakan sub-direktori terpisah yang "tidak dapat di-listing" di web akan mencegah distribusi materi sensitif. Anda dapat memastikan bahwa itu "tidak dapat di-listing" dengan menggunakan konfigurasi server. Simpan saja semua file yang tidak Anda inginkan robots.txt untuk mengunjungi dan mengindeks di sub-direktori ini.
Apakah mencantumkan halaman atau direktori dalam file robots.txt mengakibatkan akses yang tidak diinginkan?
Seperti yang telah disebutkan sebelumnya, dengan menempatkan semua file yang tidak ingin Anda indeks ke dalam sub-direktori terpisah dan kemudian membuatnya tidak dapat di-listing melalui konfigurasi server seharusnya memastikan bahwa mereka tidak muncul dalam hasil pencarian. Satu-satunya listing yang kemudian Anda lakukan di file robots.txt adalah nama direktori tersebut. Satu-satunya cara untuk mengakses file-file ini adalah melalui tautan langsung ke salah satu file tersebut.
Ini adalah contoh:
Sebagai gantinya
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Gunakan
User-Agent:*
Disallow:/norobots/
Anda kemudian perlu membuat direktori "norobots", yang mencakup foo.html dan bar.html. Perhatikan bahwa konfigurasi server Anda perlu jelas tentang tidak menghasilkan daftar direktori untuk direktori "norobots".
Ini mungkin bukan pendekatan yang sangat aman karena orang atau bot yang menyerang situs Anda masih dapat melihat bahwa Anda memiliki direktori "norobots" meskipun mereka mungkin tidak dapat melihat file di dalam direktori tersebut. Namun, seseorang dapat mempublikasikan tautan ke file-file tersebut di situs web mereka atau, yang lebih buruk lagi, tautan tersebut mungkin muncul dalam file log yang dapat diakses oleh publik (misalnya log server web sebagai referer). Kesalahan konfigurasi server juga mungkin terjadi, mengakibatkan daftar direktori.
Apa artinya ini? Robots.txt tidak dapat membantu Anda dalam mengontrol akses karena alasan sederhana bahwa itu tidak dimaksudkan untuk itu. Contoh yang baik adalah "Rambu larangan masuk." Masih ada orang yang akan melanggar instruksi tersebut.
Jika ada file yang hanya ingin Anda akses oleh orang yang berwenang, konfigurasi server akan membantu dengan otentikasi. Jika Anda menggunakan CMS (Sistem Manajemen Konten), Anda memiliki kontrol akses pada halaman individu dan koleksi sumber daya.
Bisakah Anda mengoptimalkan robots.txt untuk SEO?
Tentu saja. Panduan terbaik tentang cara mengoptimalkan robots.txt adalah konten situs. Pengingat cepat: Robots.txt seharusnya tidak pernah digunakan untuk memblokir halaman agar tidak di-crawl oleh bot mesin pencari. Gunakan hanya untuk memblokir bagian situs web Anda yang tidak dapat diakses oleh publik, misalnya, halaman login seperti wp-admin.
Ini adalah baris disallow untuk halaman login Neil Patel pada salah satu situs webnya:
User-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
Anda dapat menggunakan baris disallow ini untuk mencegah login Anda dari diindeks.
Jika ada beberapa halaman tertentu yang Anda tidak ingin diindeks, gunakan perintah yang sama seperti di atas. Sebagai contoh:
User-agent:*
Disallow:/page/
Tentukan halaman yang Anda tidak ingin diindeks setelah garis miring dan tutup dengan garis miring lainnya. Sebagai contoh:
User-agent:*
Disallow:/page/terima-kasih/
Apa saja beberapa halaman yang mungkin ingin Anda kecualikan dari diindeks?
- Konten duplikat yang disengaja. Apa maksudnya? Terkadang Anda sengaja membuat konten duplikat untuk mencapai tujuan tertentu. Contoh yang baik adalah versi cetak yang ramah dari halaman web tertentu. Anda dapat menggunakan robots.txt untuk memblokir pengindeksan versi cetak yang ramah dari konten identik tersebut.
- Halaman terima kasih. Alasan Anda ingin memblokir halaman ini dari diindeks sangat sederhana: Halaman ini seharusnya menjadi langkah terakhir dalam corong penjualan. Pada saat pengunjung Anda tiba di halaman ini, mereka seharusnya telah melewati seluruh corong penjualan. Jika halaman ini terindeks, itu berarti Anda mungkin kehilangan prospek, atau Anda akan menerima prospek palsu.
Perintah untuk memblokir halaman seperti itu adalah:
Disallow:/terima-kasih/
Noindex dan NoFollow
Seperti yang telah kami katakan sepanjang artikel ini, menggunakan robots.txt bukanlah jaminan 100% bahwa halaman Anda tidak akan terindeks. Mari kita lihat dua cara untuk memastikan bahwa halaman yang diblokir memang tidak terindeks.
Direktif noindex
Ini bekerja bersamaan dengan perintah disallow. Gunakan keduanya dalam direktif Anda, seperti dalam:
Disallow:/terima-kasih/
Direktif nofollow
Ini berfungsi untuk secara khusus memberi instruksi kepada bot Google agar tidak merayapi tautan di sebuah halaman. Ini bukan bagian dari file robots.txt. Untuk menggunakan perintah nofollow agar halaman tidak dirayapi dan diindeks, Anda perlu menemukan kode sumber dari halaman spesifik yang tidak Anda inginkan untuk diindeks.
Tempelkan ini di antara tag pembuka dan penutup head:
<meta name = “robots” content=”tanpaikuti”>
Anda dapat menggunakan “nofollow” dan “noindex” secara bersamaan. Gunakan baris kode ini:
<meta name = “robots” content=”noindex,nofollow”>
Menghasilkan robots.txt
Jika Anda merasa kesulitan untuk menulis robots.txt dengan menggunakan semua format dan sintaks yang perlu Anda pahami dan ikuti, Anda dapat menggunakan alat yang mempermudah prosesnya. Contoh yang baik adalah generator robots.txt gratis kami.
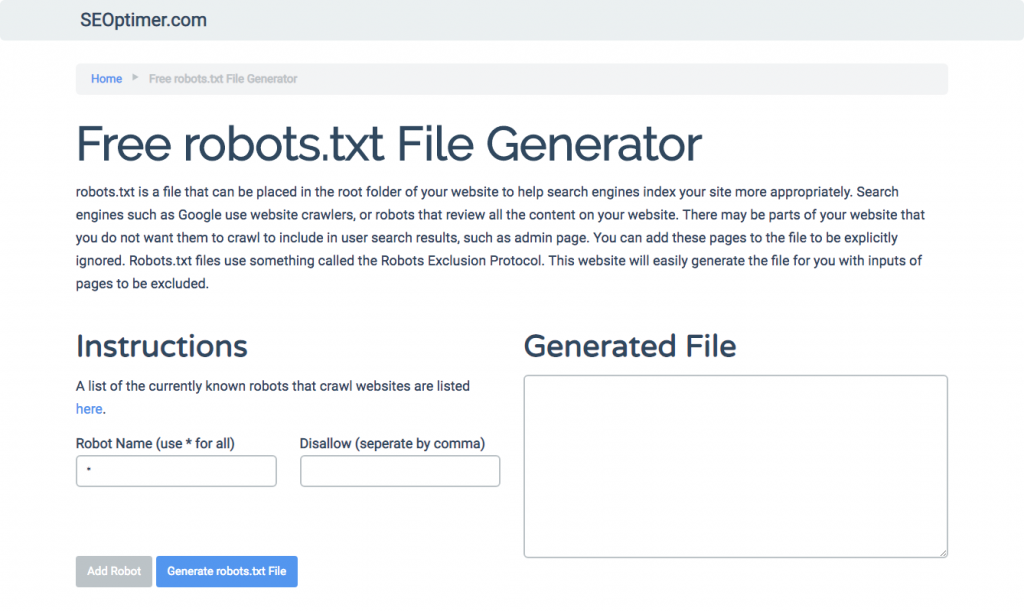
Alat ini memungkinkan Anda untuk memilih jenis hasil yang Anda butuhkan di situs web Anda dan file atau direktori yang ingin Anda tambahkan. Anda bahkan dapat menguji file Anda dan melihat bagaimana persaingan Anda berlangsung.
Menguji file robots.txt Anda
Anda perlu menguji file robots.txt Anda untuk memastikan bahwa itu bekerja sesuai yang diharapkan.
Gunakan tester robots.txt milik Google.
Untuk melakukan ini, masuk ke akun Webmaster Anda.
- Selanjutnya, pilih properti Anda. Dalam hal ini, itu adalah situs web Anda.
- Klik pada "crawl" di bilah sisi sebelah kiri.
- Klik pada "robots.txt tester."
- Ganti kode yang ada dengan file robots.txt baru Anda.
- Klik "test."
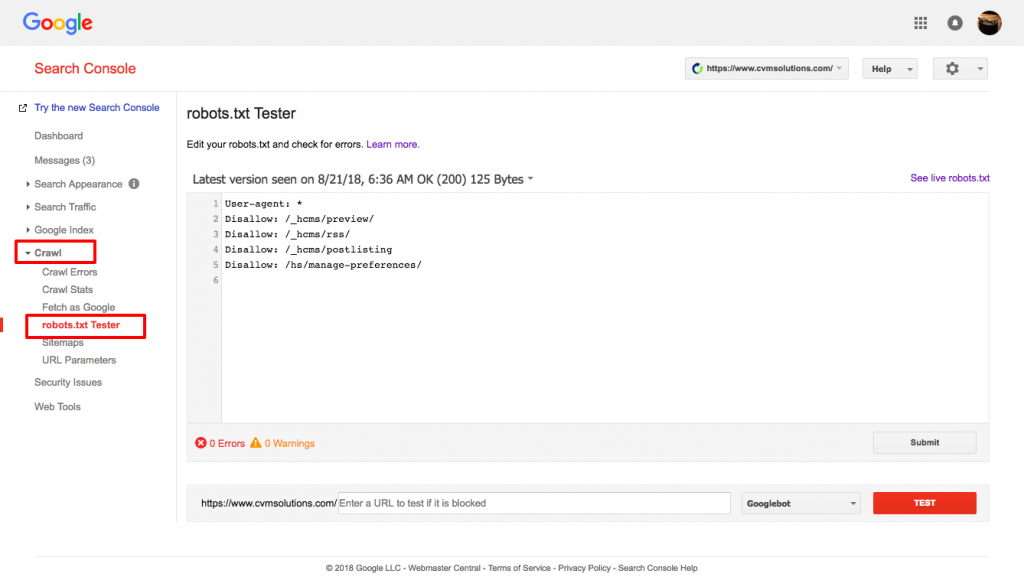
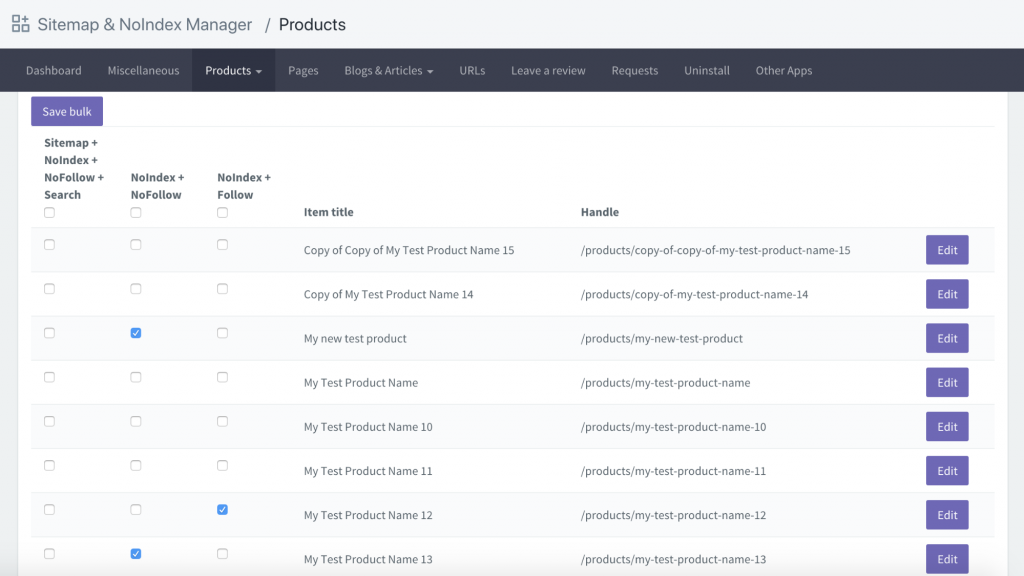
Anda seharusnya dapat melihat kotak teks "diizinkan" jika file tersebut valid. Untuk informasi lebih lanjut, periksa panduan mendalam ini di Google robots.txt tester.
Jika file Anda valid, sekarang saatnya untuk mengunggahnya ke direktori root Anda atau menyimpannya jika di sana sebagai file robots.txt lain.
Cara menambahkan robots.txt ke situs WordPress Anda
Untuk menambahkan file robots.txt ke file WordPress Anda, kami akan membahas opsi plugin dan FTP.
Untuk opsi plugin, Anda dapat menggunakan plugin seperti All in One SEO Pack
Untuk melakukan ini, masuk ke dasbor WordPress Anda
Gulir ke bawah sampai Anda menemukan "plugins"
Klik "tambah baru"
Pergi ke "cari plugin"
Ketik “All in One SEO Pack”
Instal dan aktifkan
Dalam bagian Pengaturan Umum dari plugin All in One SEO, Anda dapat mengonfigurasi aturan noindex dan nofollow untuk disertakan dalam file robots.txt Anda.
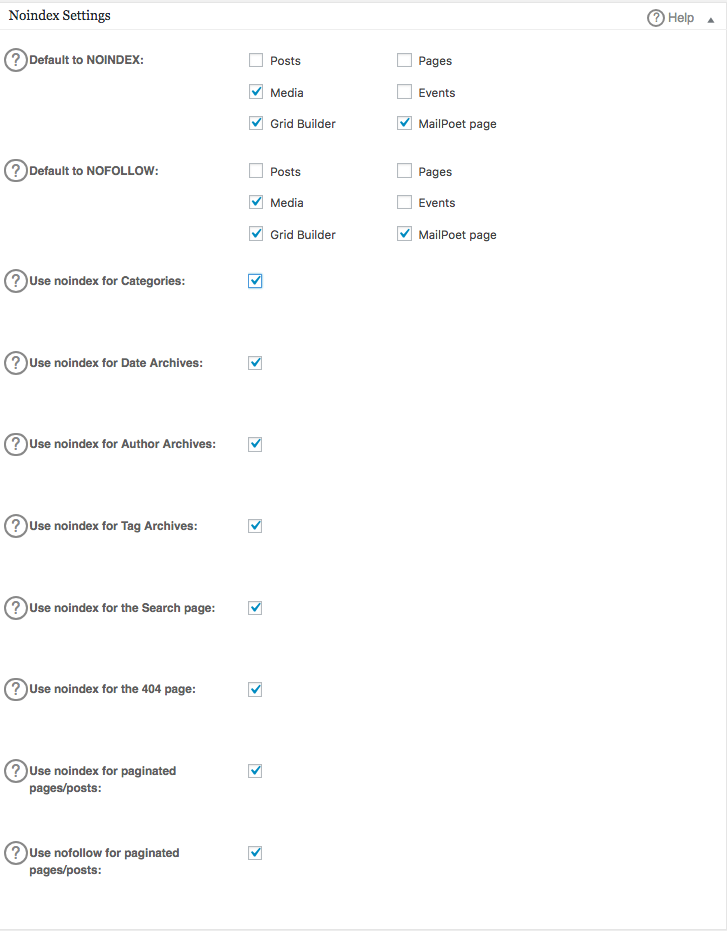
Anda dapat menentukan URL mana yang harus NOINDEX, NOFOLLOW. Meninggalkan ini tidak dicentang akan secara default diindeks:
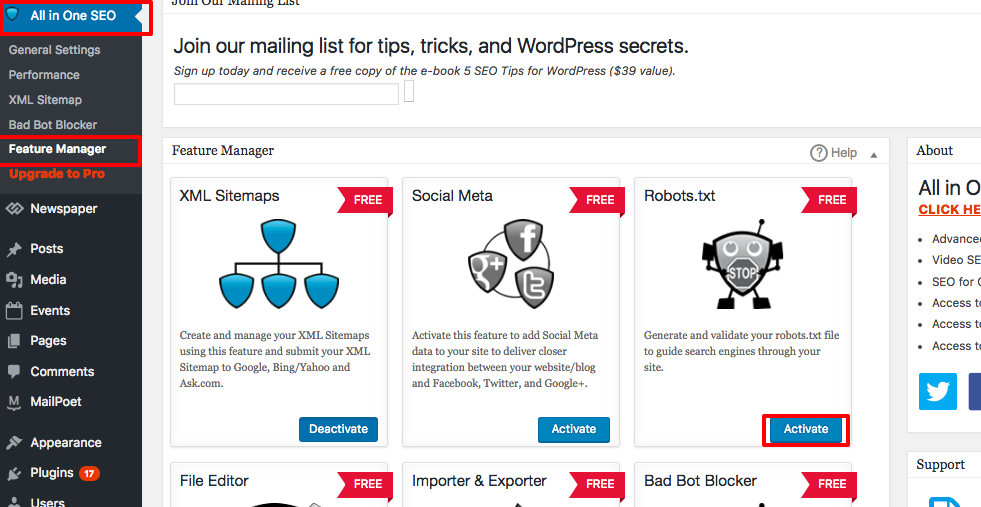
Untuk membuat aturan lanjutan di file robots.txt Anda, klik pengelola fitur, kemudian tombol aktifkan tepat di bawah robots.txt.
Robots.txt kini muncul tepat di bawah pengelola fitur. Klik pada itu. Anda akan melihat sebuah bagian yang disebut "buat file robots.txt."
Ada bagian pembuat aturan yang memungkinkan Anda untuk memilih dan mengisi aturan yang Anda inginkan untuk situs Anda, tergantung pada apa yang Anda inginkan tidak ingin diindeks.
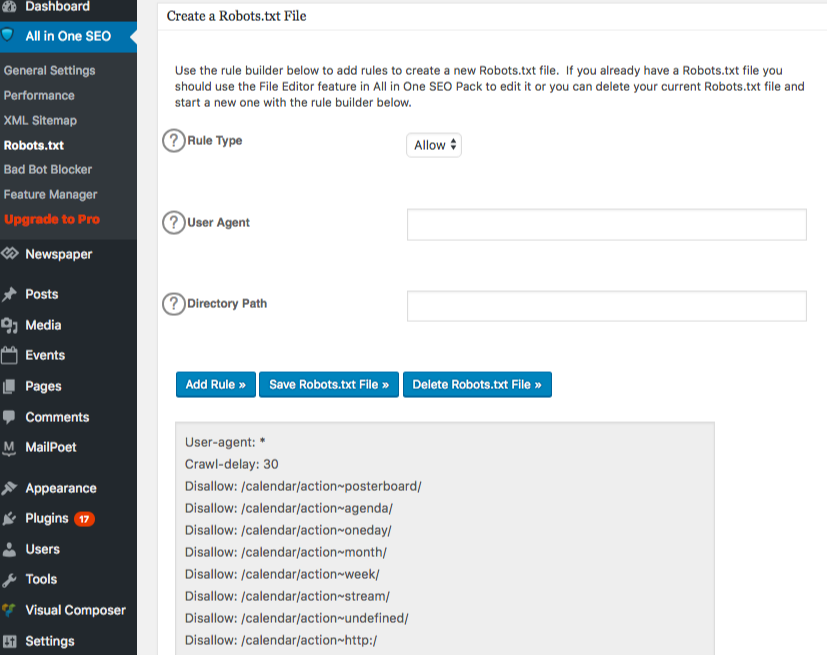
Setelah Anda selesai membuat aturan, klik "tambah aturan."
Aturan tersebut kemudian akan dicantumkan di bawah folder robots.txt yang telah dibuat.
Anda akan melihat pesan untuk menunjukkan bahwa “Semua dalam Satu Opsi” telah diperbarui.
Metode lain yang dapat Anda gunakan adalah dengan mengunggah file robots.txt Anda langsung ke klien FTP (File Transfer Protocol) Anda seperti FileZilla.
Setelah Anda membuat file robots.txt Anda, Anda dapat menemukan dan menggantinya. File robots.txt Anda akan berada di: "/applications/[NAMA FOLDER]/public_html."
Cara mengedit file robots.txt pada Wix Anda
Wix menghasilkan file robots.txt untuk situs web yang menggunakan platform pembuatan web. Untuk melihatnya, tambahkan “/robots.txt” ke domain Anda. File yang ditambahkan ke robots.txt berkaitan dengan struktur situs Wix, misalnya, tautan noflashhtml, yang tidak berkontribusi pada nilai SEO dari situs Wix Anda.
Anda tidak dapat mengedit file robots.txt jika situs Anda ditenagai oleh Wix. Anda hanya dapat menggunakan opsi lain seperti menambahkan "tag noindex" ke halaman yang tidak ingin Anda indeks.
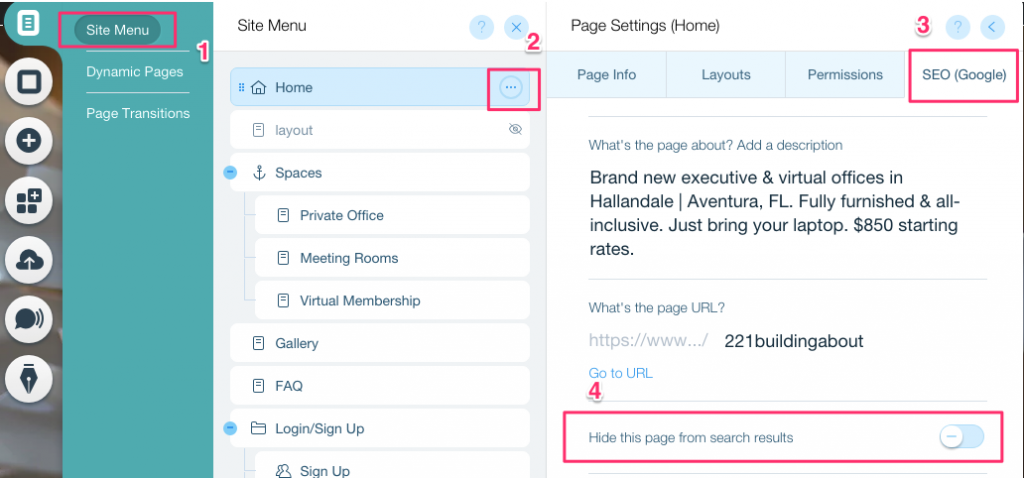
Untuk membuat tag noindex untuk halaman tertentu:
- Klik pada Menu Situs
- Klik pada opsi Pengaturan untuk halaman tersebut
- Pilih Tag SEO (Google)
- Aktifkan Sembunyikan halaman ini dari hasil pencarian
Cara mengedit file robots.txt pada Shopify Anda
Sama seperti dengan Wix, Shopify secara otomatis menambahkan file robots.txt yang tidak dapat diedit ke situs Anda. Jika Anda tidak ingin beberapa halaman diindeks, Anda perlu menambahkan "tag noindex" atau tidak menerbitkan halaman tersebut. Anda juga dapat menambahkan meta tag di bagian header dari halaman-halaman yang tidak Anda inginkan untuk diindeks. Ini adalah yang harus Anda tambahkan ke header Anda:
<meta name= “robots” content = “noindex”>
Shopify telah membuat panduan yang lengkap tentang cara menyembunyikan halaman dari mesin pencari yang dapat Anda ikuti.
Opsi lainnya adalah mengunduh aplikasi yang bernama Sitemap & NoIndex Manager oleh Orbis Labs. Anda dapat dengan mudah menandai opsi noindex atau nofollow untuk setiap halaman di situs Shopify Anda: