Hvad er Robots.txt?
Robots.txt er en fil i tekstform, der instruerer bot-crawlere om at indeksere eller ikke indeksere bestemte sider. Det er også kendt som portvogteren for hele dit websted. Bot-crawleres første mål er at finde og læse robots.txt-filen, før de får adgang til dit sitemap eller nogen sider eller mapper.
Med robots.txt kan du mere specifikt:
- Reguler hvordan søgemaskinebots crawler din side
- Giv visse adgang
- Hjælp søgemaskine-spiders med at indeksere sidens indhold
- Vis hvordan indhold skal serveres til brugere
Robots.txt er en del af Robots Exclusion Protocol (R.E.P), bestående af site/side/URL niveau direktiver. Mens søgemaskinebots stadig kan crawle hele din side, er det op til dig at hjælpe dem med at beslutte, om visse sider er værd at bruge tid og kræfter på.
Hvorfor du har brug for Robots.txt
Din side behøver ikke en robots.txt-fil for at fungere korrekt. De vigtigste grunde til, at du har brug for en robots.txt-fil, er, så når bots crawler din side, beder de om tilladelse til at crawle, så de kan forsøge at hente oplysninger om siden til indeksering. Derudover beder en hjemmeside uden en robots.txt-fil grundlæggende bot-crawlere om at indeksere siden, som de finder passende. Det er vigtigt at forstå, at bots stadig vil crawle din side uden robots.txt-filen.
Placeringen af din robots.txt-fil er også vigtig, fordi alle bots vil lede efter www.123.com/robots.txt. Hvis de ikke finder noget der, vil de antage, at siden ikke har en robots.txt-fil og indeksere alt. Filen skal være en ASCII- eller UTF-8-tekstfil. Det er også vigtigt at bemærke, at reglerne er case-sensitive.
Her er nogle ting, som robots.txt vil og ikke vil gøre:
- Filen er i stand til at kontrollere adgang for crawlere til bestemte områder af dit website. Du skal være meget forsigtig, når du opsætter robots.txt, da det er muligt at blokere hele websitet fra at blive indekseret.
- Det forhindrer duplikeret indhold i at blive indekseret og vises i søgeresultater.
- Filen specificerer crawl-forsinkelsen for at forhindre servere i at blive overbelastet, når crawlerne indlæser flere stykker indhold på samme tid.
Her er nogle Googlebots, der måske crawler på din side fra tid til anden:
| Web Crawler | Brugeragentstreng |
| Googlebot Nyheder | Googlebot-News |
| Googlebot Billeder | Googlebot-Image/1.0 |
| Googlebot Video | Googlebot-Video/1.0 |
| Google Mobil (fremhævet telefon) | SAMSUNG-SGH-E250/1.0 Profil/MIDP-2.0 Konfiguration/CLDC-1.1 UP.Browser/6.2.3.3.c.1.101 (GUI) MMP/2.0 (kompatibel; Googlebot-Mobile/2.1; +http://www.google.com/bot.html) |
| Google Smartphone | Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) |
| Google Mobile Adsense | (kompatibel; Mediapartners-Google/2.1; +http://www.google.com/bot.html) |
| Google Adsense | Mediapartners-Google |
| Google AdsBot (PPC landingsidekvalitet) | AdsBot-Google (+http://www.google.com/adsbot.html) |
| Google app crawler (hent ressourcer til mobil) | AdsBot-Google-Mobile-Apps |
Du kan finde en liste over yderligere bots her.
- Filerne hjælper med at specificere placeringen af sitemaps.
- Det forhindrer også søgemaskinebots i at indeksere forskellige filer på hjemmesiden såsom billeder og PDF'er.
Når en bot ønsker at besøge din hjemmeside (for eksempel, www.123.com), tjekker den først for www.123.com/robots.txt og finder:
Bruger-agent: *
Disallow: /
Dette eksempel instruerer alle (User-agents*) søgemaskinebots til ikke at indeksere (Disallow: /) hjemmesiden.
Hvis du fjernede skråstregen fra Disallow, som i eksemplet nedenfor,
Bruger-agent: *
Forbyd:
de bots ville være i stand til at crawle og indeksere alt på hjemmesiden. Dette er grunden til, at det er vigtigt at forstå syntaksen af robots.txt.
Forståelse af robots.txt syntaks
Robots.txt syntaks kan betragtes som "sproget" i robots.txt filer. Der er 5 almindelige termer, du sandsynligvis vil støde på i en robots.txt fil. De er:
- User-agent: Den specifikke webcrawler, som du giver crawl-instruktioner (normalt en søgemaskine). En liste over de fleste user agents kan findes her.
- Forbyd: Kommandoen, der bruges til at fortælle en brugeragent ikke at gennemgå en bestemt URL. Kun én "Forbyd:" linje er tilladt for hver URL.
- Tillad (Kun gældende for Googlebot): Kommandoen fortæller Googlebot, at den kan få adgang til en side eller undermappe, selvom dens overordnede side eller undermappe måske er forbudt.
- Crawl-delay: Antallet af millisekunder, en crawler skal vente, før den indlæser og crawler sideindhold. Bemærk, at Googlebot ikke anerkender denne kommando, men crawl rate kan indstilles i Google Search Console.
- Sitemap: Bruges til at angive placeringen af enhver XML-sitemap(er) forbundet med en URL. Bemærk, at denne kommando kun understøttes af Google, Ask, Bing og Yahoo.
Robots.txt instruktionsresultater
Du forventer tre resultater, når du udsteder robots.txt-instruktioner:
- Fuld tilladelse
- Fuld afvisning
- Betinget tilladelse
Lad os undersøge hver enkelt nedenfor.
Fuld tilladelse
Dette resultat betyder, at alt indhold på din hjemmeside kan blive crawlet. Robots.txt-filer er beregnet til at blokere crawling af søgemaskinebots, så denne kommando kan være meget vigtig.
Dette resultat kunne betyde, at du slet ikke har en robots.txt-fil på din hjemmeside. Selv hvis du ikke har den, vil søgemaskinebots stadig lede efter den på din side. Hvis de ikke finder den, vil de gennemgå alle dele af din hjemmeside.
Den anden mulighed under dette udfald er at oprette en robots.txt-fil, men holde den tom. Når spideren kommer for at crawle, vil den identificere og endda læse robots.txt-filen. Da den ikke vil finde noget der, vil den fortsætte med at crawle resten af siden.
Hvis du har en robots.txt-fil og har følgende to linjer i den,
Bruger-agent:*
Forbyd:
søgemaskinens spider vil gennemgå din hjemmeside, identificere robots.txt-filen og læse den. Den vil nå til linje to og derefter fortsætte med at gennemgå resten af siden.
Fuld afvisning
Her vil intet indhold blive crawlet og indekseret. Denne kommando udstedes af denne linje:
Bruger-agent:*
Disallow:/
Når vi taler om [ingen indhold], mener vi, at intet fra hjemmesiden (indhold, sider, osv.) kan crawles. Dette er aldrig en god idé.
Betinget Tillad
Dette betyder, at kun bestemt indhold på hjemmesiden kan gennemsøges.
En betinget tilladelse har dette format:
Bruger-agent:*
Disallow:/
User-agent: Mediapartner-Google
Tillad:/
Du kan finde den fulde robots.txt syntaks her.
Bemærk, at blokerede sider stadig kan indekseres, selvom du har nægtet URL'en som vist på billedet nedenfor:
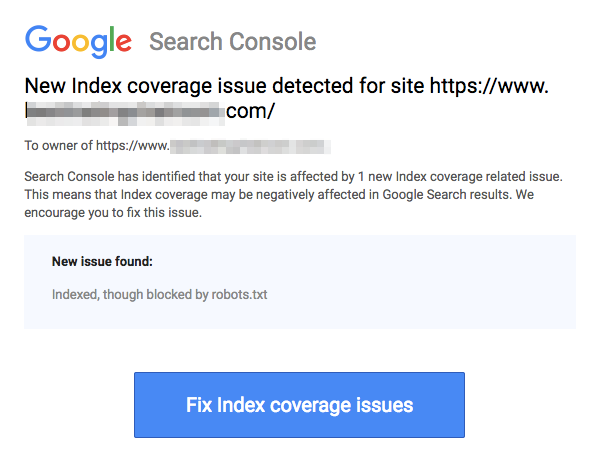
Du kan modtage en e-mail fra søgemaskiner om, at din URL er blevet indekseret som på skærmbilledet ovenfor. Hvis din ikke-tilladte URL er linket fra andre sider, såsom ankertekst i links, vil den blive indekseret. Løsningen på dette er at 1) beskytte dine filer med adgangskode på din server, 2) bruge noindex meta tag, eller 3) fjerne siden helt.
Kan en robot stadig scanne igennem og ignorere min robots.txt-fil?
Ja. det er muligt, at en robot kan omgå robots.txt. Dette skyldes, at Google bruger andre faktorer som ekstern information og indgående links til at bestemme, om en side skal indekseres eller ej. Hvis du ikke ønsker, at en side skal indekseres overhovedet, bør du anvende noindex robots meta tag. En anden mulighed ville være at bruge X-Robots-Tag HTTP header.
Kan jeg blokere kun dårlige robotter?
Det er muligt at blokere dårlige robotter i teorien, men det kan være svært at gøre det i praksis. Lad os se på nogle måder at gøre det på:
- Du kan blokere en dårlig robot ved at udelukke den. Du skal dog kende navnet på den pågældende robot, som scanner i User-Agent-feltet. Du skal derefter tilføje en sektion i din robots.txt-fil, der udelukker den dårlige robot.
- Serverkonfiguration. Dette ville kun fungere, hvis den dårlige robots operation er fra en enkelt IP-adresse. Serverkonfiguration eller en netværksfirewall vil blokere den dårlige robot fra at få adgang til din webserver.
- Brug af avancerede firewall-regelkonfigurationer. Disse vil automatisk blokere adgang til de forskellige IP-adresser, hvor kopier af den dårlige robot findes. Et godt eksempel på bots, der opererer på forskellige IP-adresser, er i tilfælde af kaprede pc'er, som endda kunne være en del af et større Botnet (læs mere om Botnet her).
Hvis den dårlige robot opererer fra en enkelt IP-adresse, kan du blokere dens adgang til din webserver gennem serverkonfiguration eller med en netværksfirewall.
Hvis kopier af robotten opererer på et antal forskellige IP-adresser, bliver det sværere at blokere dem. Den bedste mulighed i dette tilfælde er at bruge avancerede firewall-regelkonfigurationer, der automatisk blokerer adgang til IP-adresser, der laver mange forbindelser; desværre kan dette også påvirke adgangen for gode bots.
Hvad er nogle af de bedste SEO-praksisser, når man bruger robots.txt?
På dette tidspunkt spekulerer du måske på, hvordan du navigerer i disse meget vanskelige robots.txt farvande. Lad os se nærmere på dette:
- Sørg for, at du ikke blokerer noget indhold eller sektioner af din side, som du vil have crawlet.
- Brug en blokeringsmekanisme, der er forskellig fra robots.txt, hvis du vil have linkværdi til at blive overført fra en side med robots.txt (hvilket betyder, at den er praktisk talt blokeret) til linkdestinationen.
- Brug ikke robots.txt til at forhindre følsomme data såsom private brugeroplysninger i at dukke op i søgeresultater. At gøre det kan tillade andre sider at linke til sider, der indeholder private brugeroplysninger, hvilket kan medføre, at siden bliver indekseret. I dette tilfælde er robots.txt blevet omgået. Andre muligheder, som du kan udforske her, er adgangskodebeskyttelse eller noindex meta direktiv.
- Der er ikke behov for at specificere direktiver for hver af en søgemaskines crawlere, da de fleste brugeragenter, hvis de tilhører den samme søgemaskine, følger de samme regler. Google bruger Googlebot til søgemaskiner og Googlebot Image til billedsøgninger. Den eneste fordel ved at vide, hvordan man specificerer hver crawler, er, at du er i stand til at finjustere præcis, hvordan indholdet på din side crawles.
- Hvis du har ændret robots.txt-filen og du vil have Google til at opdatere den hurtigere, skal du indsende den direkte til Google. For instruktioner om hvordan du gør det, klik her. Det er vigtigt at bemærke, at søgemaskiner cacher robots.txt-indhold og opdaterer det cachede indhold mindst en gang om dagen.
Grundlæggende robots.txt retningslinjer
Nu hvor du har en grundlæggende forståelse af SEO i forhold til robots.txt, hvilke ting skal du huske på, når du bruger robots.txt? I dette afsnit ser vi på nogle retningslinjer, der skal følges, når du bruger robots.txt, selvom det er vigtigt faktisk at læse hele syntaksen.
Format og placering
Den teksteditor, som du vælger at bruge til at oprette en robots.txt-fil, skal kunne oprette standard ASCII- eller UTF-8-tekstfiler. At bruge en tekstbehandler er ikke en god idé, da nogle tegn, som kan påvirke crawling, kan blive tilføjet.
Mens næsten enhver teksteditor kan bruges til at oprette din robots.txt-fil, dette værktøj anbefales stærkt, da det tillader test mod din side.
Her er flere retningslinjer om format og placering:
- Du skal navngive filen, du opretter, “robots.txt”, fordi filen er case-sensitiv. Ingen store bogstaver bruges.
- Du kan kun have én robots.txt-fil på hele siden.
- Filen robots.txt er kun placeret ét sted: roden af webstedets vært, som den er gældende for. Bemærk, at den ikke kan placeres i en underkatalog. Hvis dit websted erhttp://www.123.com/, så placeringen af robots.txt erhttp://www.123.com/robots.txt, ikke http://www.123.com/pages/robots.txt. Bemærk, at robots.txt-filen kan gælde for underdomæner (http://website.123.com/robots.txt) og endda ikke-standard porte, såsom http://www.123.com: 8181/robots.txt
Som nævnt tidligere, er robots.txt ikke den bedste måde at forhindre følsomme personlige oplysninger i at blive indekseret. Dette er en gyldig bekymring, især nu med den nyligt implementerede GDPR. Databeskyttelse bør ikke kompromitteres. Punktum.
Hvordan sikrer du så, at robots.txt ikke viser følsomme data i søgeresultater?
Brug af en separat underkatalog, der er "unlistable" på nettet, vil forhindre distribution af følsomt materiale. Du kan sikre, at det er "unlistable" ved at bruge serverkonfiguration. Opbevar blot alle de filer, som du ikke ønsker, at robots.txt skal besøge og indeksere, i denne underkatalog.
Medfører det ikke utilsigtet adgang at liste sider eller mapper i robots.txt-filen?
Som nævnt ovenfor, bør det at placere alle de filer, som du ikke ønsker indekseret, i en separat underkatalog og derefter gøre den ikke-listbar via serverkonfigurationer sikre, at de ikke vises i søgeresultaterne. Den eneste liste, du derefter vil lave i robots.txt-filen, er katalognavnet. Den eneste måde at få adgang til disse filer på er via et direkte link til en af filerne.
Her er et eksempel:
I stedet for
User-Agent:*
Disallow:/foo.html
Disallow:/bar.html
Brug
User-Agent:*
Disallow:/norobots/
Du skal derefter oprette en “norobots” mappe, som inkluderer foo.html og bar.html. Bemærk, at dine serverkonfigurationer skal være klare om ikke at generere en mappeliste for “norobots” mappen.
Dette er muligvis ikke en særlig sikker tilgang, fordi personen eller botten, der angriber dit site, stadig kan se, at du har en “norobots” mappe, selvom de måske ikke kan se filerne inde i mappen. Dog kunne nogen offentliggøre et link til disse filer på deres hjemmeside eller, endnu værre, linket kan dukke op i en logfil, der er tilgængelig for offentligheden (f.eks. en webserverlog som en henviser). En serverfejlkonfiguration er også mulig, hvilket resulterer i en mappeoversigt.
Hvad betyder dette? Robots.txt kan ikke hjælpe dig med at kontrollere adgang af den simple grund, at det ikke er beregnet til det. Et godt eksempel er et “Ingen adgang-skilt.” Der er mennesker, der stadig vil overtræde instruktionen.
Hvis der er filer, som du kun ønsker skal tilgås af autoriserede personer, vil serverkonfigurationer hjælpe med godkendelse. Hvis du bruger et CMS (Content Management System), har du adgangskontroller på individuelle sider og ressourceindsamling.
Kan du optimere robots.txt til SEO?
Absolut. Den bedste guide til, hvordan man optimerer robots.txt, er webstedets indhold. En hurtig påmindelse: Robots.txt bør aldrig bruges til at blokere sider fra at blive crawlet af søgemaskinebots. Brug det kun til at blokere de sektioner af dit websted, der ikke er tilgængelige for offentligheden, for eksempel login-sider som wp-admin.
Dette er disallow-linjen for Neil Patel’s login-side på en af hans hjemmesider:
Bruger-agent:*
Disallow:/wp-admin/
Allow:/wp-admin/admin-ajax.php
Du kan bruge denne "disallow" linje til at blokere din login fra at blive indekseret.
Hvis der er nogle specifikke sider, som du ikke ønsker at få indekseret, skal du bruge den samme kommando som ovenfor. Et eksempel:
Bruger-agent:*
Disallow:/side/
Angiv den side, som du ikke ønsker at få indekseret efter skråstregen og afslut med en anden skråstreg. For eksempel:
Bruger-agent:*
Disallow:/side/tak/
Hvilke sider vil du måske ønske at udelukke fra at blive indekseret?
- Duplikeret indhold, der er forsætligt. Hvad betyder dette? Nogle gange opretter du forsætligt duplikeret indhold for at opnå et bestemt formål. Et godt eksempel er en printervenlig version af en bestemt webside. Du kan bruge robots.txt til at blokere indekseringen af den printervenlige version af det identiske indhold.
- Tak-sider. Årsagen til, at du vil blokere denne side fra at blive indekseret, er enkel: Den er beregnet til at være det sidste trin i salgstragten. Når dine besøgende når denne side, skulle de have gennemgået hele salgstragten. Hvis denne side bliver indekseret, betyder det, at du kan gå glip af leads, eller at du vil modtage falske leads.
Kommandoen til at blokere en sådan side er:
Disallow:/tak/
Noindex og NoFollow
Som vi har sagt gennem hele denne artikel, er brugen af robots.txt ikke en 100% garanti for, at din side ikke bliver indekseret. Lad os se på to måder at sikre, at din blokerede side faktisk ikke bliver indekseret.
Noindex-direktivet
Dette fungerer sammen med disallow-kommandoen. Brug begge i din direktiv, som i:
Disallow:/tak/
Nofollow-direktivet
Dette fungerer til specifikt at instruere Google bots om ikke at crawle linksene på en side. Dette er ikke en del af robots.txt-filen. For at bruge nofollow-kommandoen til at blokere sider fra at blive crawlet og indekseret, skal du finde kildekoden for den specifikke side, som du ikke vil have indekseret.
Indsæt dette mellem de åbne og lukkede head-tags:
<meta name = “robots” content=”nofollow”>
Du kan bruge både "nofollow" og "noindex" samtidigt. Brug denne linje kode:
<meta name = “robots” content=”noindex,nofollow”>
Genererer robots.txt
Hvis du finder det svært at skrive robots.txt ved hjælp af alle de nødvendige formater og syntaks, som du skal forstå og følge, kan du bruge værktøjer, der forenkler processen. Et godt eksempel er vores gratis robots.txt generator.
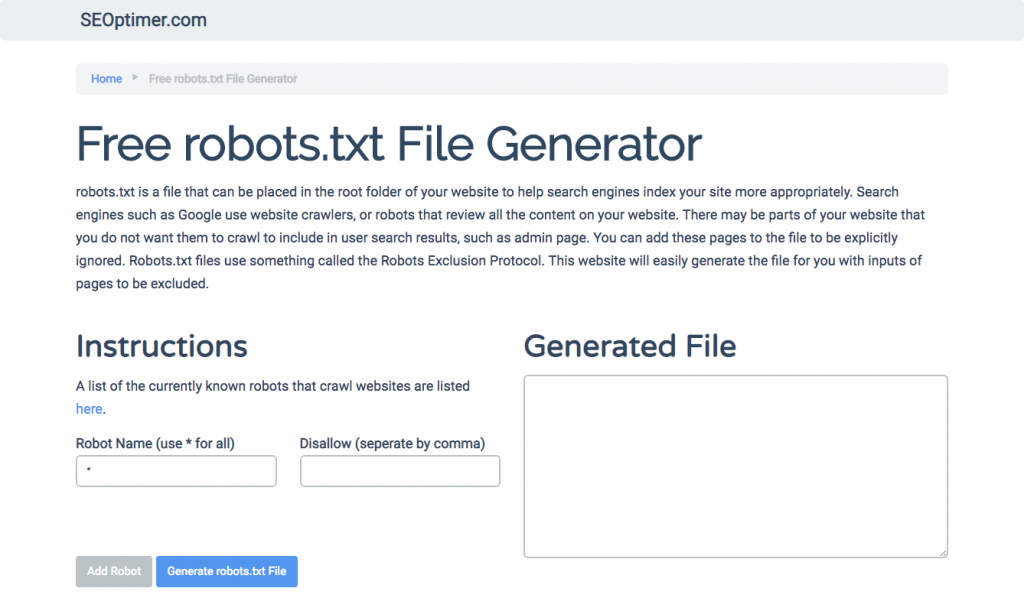
Dette værktøj giver dig mulighed for at vælge den type resultat, du har brug for på din hjemmeside, og de filer eller mapper, du vil tilføje. Du kan endda teste din fil og se, hvordan din konkurrence klarer sig.
Testning af din robots.txt-fil
Du skal teste din robots.txt-fil for at sikre, at den fungerer som forventet.
Brug Google’s robots.txt tester.
For at gøre dette, log ind på din Webmaster-konto.
- Dernæst skal du vælge din ejendom. I dette tilfælde er det din hjemmeside.
- Klik på “crawl” i venstre sidebjælke.
- Klik på “robots.txt tester.”
- Erstat enhver eksisterende kode med din nye robots.txt-fil.
- Klik på “test.”
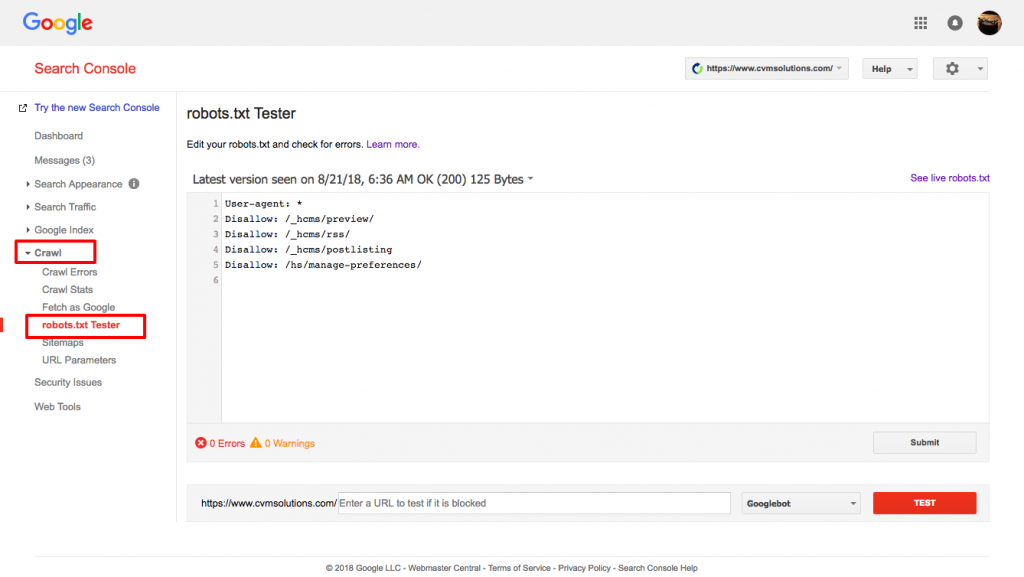
Du bør kunne se en tekstboks "tilladt", hvis filen er gyldig. For mere information, se denne dybdegående guide til Google robots.txt tester.
Hvis din fil er gyldig, er det nu tid til at uploade den til din rodmappe eller gemme den, hvis der er en anden robots.txt-fil.
Hvordan tilføjer man robots.txt til din WordPress-side
For at tilføje en robots.txt-fil til din WordPress-fil, vil vi dække plugin- og FTP-muligheder.
For [plugin] [option], du kan bruge en [plug-in] som All in One SEO Pack
For at gøre dette, log ind på din WordPress-dashboard
Rul ned, indtil du kommer til "plugins"
Klik på "tilføj ny"
Gå til "søg plugins"
Skriv “All in One SEO Pack”
Installer det og aktiver
Under [Generelle indstillinger] sektionen af All in One SEO plugin, kan du konfigurere [noindex] og [nofollow] reglerne til at blive inkluderet i din robots.txt fil.
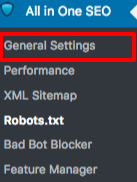
Du kan angive, hvilke URL'er der skal være NOINDEX, NOFOLLOW. Hvis du lader disse være ukontrollerede, vil de som standard blive indekseret:
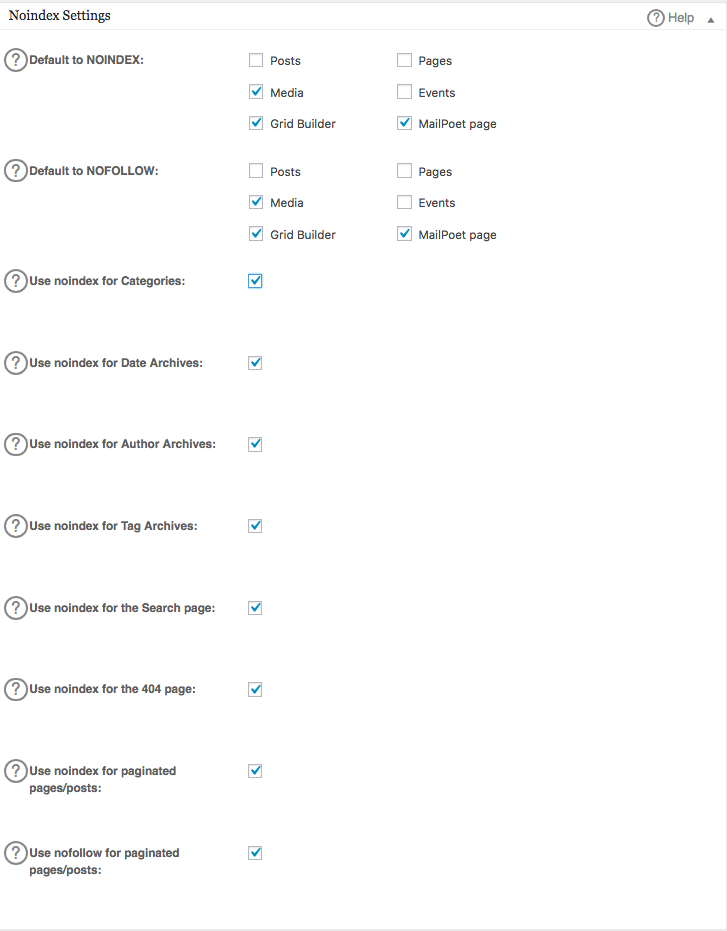
For at oprette avancerede regler i din robots.txt-fil, klik på funktionsadministratoren, og klik derefter på aktiveringsknappen lige under robots.txt.
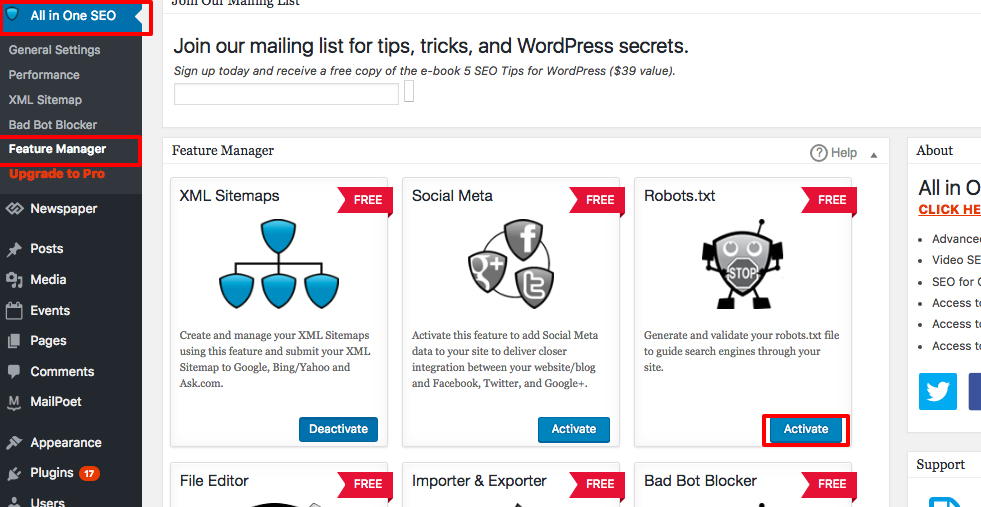
Robots.txt vises nu lige under funktionsmanageren. Klik på det. Du vil se en sektion kaldet “opret en robots.txt-fil.”
Der er en regelbyggersektion, som giver dig mulighed for at vælge og udfylde de regler, du ønsker for dit site, afhængigt af hvad du ikke ønsker indekseret.
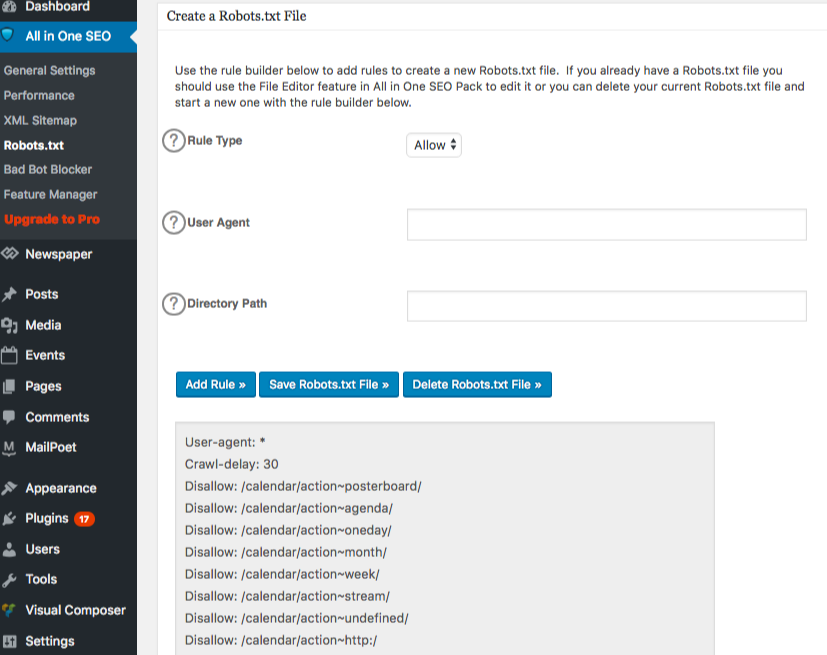
Når du er færdig med at oprette reglen, skal du klikke på “tilføj regel.”
Reglen vil derefter blive opført under mappen robots.txt, der er oprettet.
Du vil se en besked, der angiver, at "All in One Options" er blevet opdateret.
En anden metode, du kan bruge, er at uploade din robots.txt-fil direkte til din FTP (File Transfer Protocol) klient som FileZilla.
Når du har genereret din robots.txt-fil, kan du finde og erstatte den. Din robots.txt-fil vil være placeret i: “/applications/[FOLDER NAME]/public_html.”
Sådan redigerer du robots.txt-filen på din Wix
Wix genererer en robots.txt-fil for websites, der bruger webbygningsplatformen. For at se den, tilføj “/robots.txt” til dit domæne. De filer, der tilføjes til robots.txt, har at gøre med strukturen af Wix-sider, for eksempel noflashhtml links, som ikke bidrager til SEO-værdien af din Wix-drevne side.
Du kan ikke redigere din robots.txt-fil, hvis dit site er drevet af Wix. Du kan kun bruge andre muligheder som at tilføje en “noindex tag” til de sider, som du ikke ønsker skal indekseres.
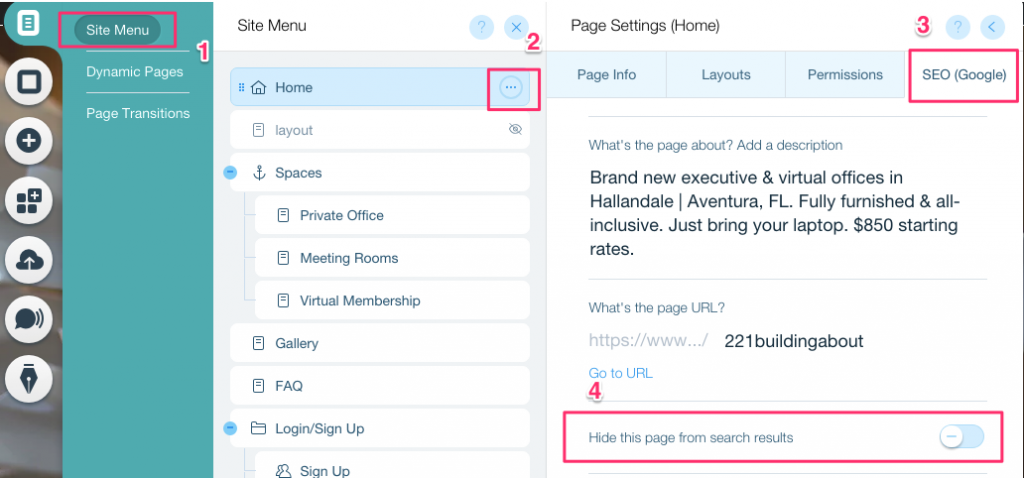
For at oprette et noindex-tag for en specifik side:
- Klik på Site Menu
- Klik på Indstilling muligheden for den specifikke side
- Vælg SEO (Google) tag
- Slå Skjul denne side fra søgeresultater til
Sådan redigerer du robots.txt-filen på din Shopify
Præcis som med Wix, tilføjer Shopify automatisk en ikke-redigerbar robots.txt-fil til dit site. Hvis du ikke ønsker, at nogle sider indekseres, skal du tilføje “noindex tag” eller afpublicere siden. Du kan også tilføje meta tags i header-sektionen på de sider, du ikke ønsker skal indekseres. Dette er, hvad du skal tilføje til din header:
<meta name= “robots” content = “noindex”>
Shopify har lavet en grundig guide om, hvordan man skjuler sider fra søgemaskiner, som du kan følge.
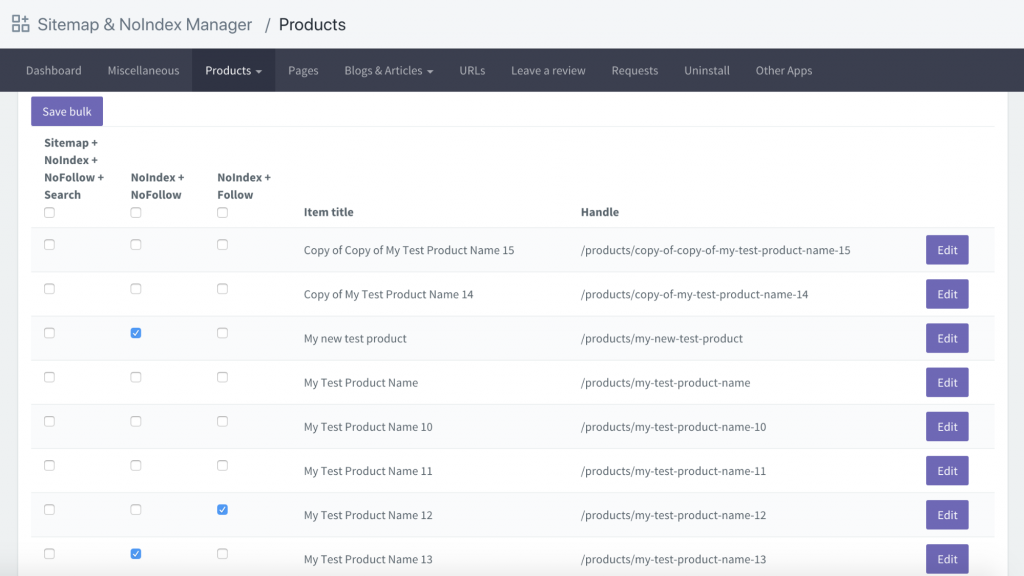
En anden mulighed er at downloade en app kaldet Sitemap & NoIndex Manager af Orbis Labs. Du kan simpelthen markere noindex eller nofollow mulighederne for hver side på din Shopify-side: